This project involved extending the DLXsim, the simulator written in the University of California at Berkeley, to be a DLX pipeline simulator. The DLX pipeline and the DLX instruction set architecture are described in Computer Architecture, A Quantitative Approach by Hennessy and Patterson ([1]). The instructions execution in the extended DLXsim is pipelined. Each instruction takes at least five clock cycles to complete (there are five pipe stages), and the user can trace what is happening at each stage at any moment of time. The simulator gives the opportunity to use integer and floating point instructions and supports the whole DLX instruction set introduced in [1]. It also gives additional statistics values as compared to the ones described in [2]. This report contains a brief overview of the DLX pipeline architecture followed by the detailed discussion on the simulator implementation issues. It also includes an example of an interactive session with DLXsim with the focus on examining pipeline features. The expectation is that the major use of this tool will be in Computer Architecture classes to help the students in understanding what pipeline is, what problems it may cause and how to deal with them.
The pipeline implemented in this simulator is the standard DLX pipeline described in Chapter 3 of [1]. It is the five stages pipeline where new instruction is fetched on each clock cycle and one instruction completes its execution at each cycle (provided, of course, that no hazards occur).
DLX pipeline consists of five stages:
The first two stages are the same for all types of instructions:
Now, when it is known what kind of instruction it is, different actions can be done according to that. Obviously, EX, MEM and WB stages are different for different groups of instructions. Three major groups are: arithmetic instructions, load/stores and control instructions (branches and jumps). For each of the groups the content of the last three pipe stages is as follows:
The software implementation of the simulator of this kind of pipeline is discussed in further sections.
Floating point instructions create more complications for the pipeline. The reason is that the EX stage takes more than one clock cycle for most of the floating point instructions. Being an intricacy by itself it causes another one: overlapping of integer and floating point instructions in MEM or in WB stages. To simplify pipeline control in this case, the integer and floating point registers are separated in two different register files, each with its own read/write port. This implies that one integer and one fp instruction can be in the same pipe stage (MEM or WB) at the same clock cycle, however, two instructions of the same kind cannot. This situation will not arise for integer instructions: they issue one-by-one and each of them takes the same time, whereas two floating point instructions can finish EX stage at the same clock cycle. In this case one of the instructions has to stall. The instruction which is stalled is the one with the smaller latency.
This was just a brief overview of DLX pipeline and we assumed that the user is familiar with the general concept of pipelining. For detailed discussion on this topic refer to Chapters 3 and 4 of [1].
The core function of the pipeline Simulator is the function Pipe_Simulate contained in the file pipe.c. Here we discuss the main points of this function.
The information about each pipeline stage is contained in the array machPtr-->stages. This array has an entry corresponding to each stage and is indexed according to that (e.g. machPtr-->stages[IF], machPtr-->stages[ID], etc.). Elements of the array are the structures of the type InstrInExec. Here is the meaning of all the fields of this structure:
The list of the floating point instructions in the EX stage at any point of time is called Pipe_FPopsList and is a linked list of the structures described above.
Another data structure used for the pipeline management is res_for_bypass. This structure contains the information about the values to be bypassed and has the following fields:
The array to manage bypassing is machPtr-->bypass with the elements being pointers to structures of the type described above. The details on how bypassing is implemented can be found in later sections.
Let us consider the Pipe_Simulation function. One execution of the while loop in this function is equivalent to one clock cycle of the simulated machine. At any clock cycle there can be up to five integer different instructions in the pipeline: one for each pipeline stage. For each of the stages the corresponding element of the array machPtr-->stages describes its state. When the new execution of the loop starts (i.e. simulation of a new clock cycle), each element contains the instruction that is entering this pipeline stage.
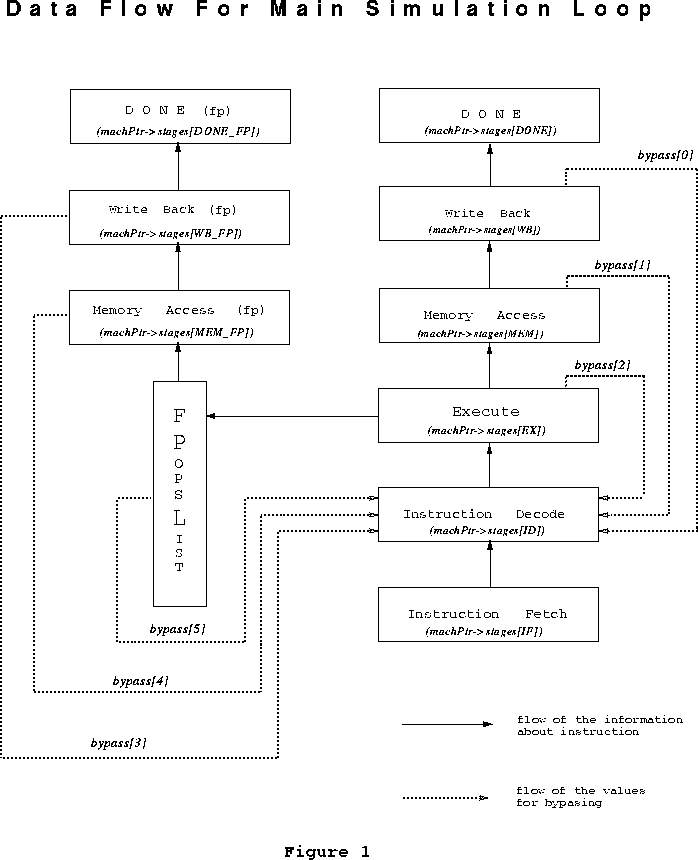
The stages are analized in the loop in the following order: Write Back, Memory Access, Execute, Instruction Decode and the last one is Instruction Fetch. This order was chosen because of the following reason: the instruction information needs to be passed from earlier stages in the pipeline to the later ones. There are two places in the loop where it can be done: at the end of the processing of each stage, or at the end of the whole loop for all of the stages. The first option is more convenient because it does not require storing of any additional information in the course of loop execution. So, when whatever needs to be done at the stage i is done, all the instruction information is copied in the variable describing the next stage. For better understanding of the following discussion about data flow in the main simulation loop, refer to Figure 1.
Everything needed to process each particular stage is contained in the corresponding structure machPtr-->stages[i]. There are common steps in the processing of each stage of the pipeline:
Events that happen on each pipe stage are close to the ones described in [1]. Here is a detailed description of what the simulator does at each pipe stage:
Another problem which is dealt with during the ID stage, is execution of branches and jumps. Branch decisions are made at this stage and the program counter is modified here. Here arises one more case when the pipeline has to stall: if the value of the register to be checked as branch condition is being computed in the EX stage at the same clock cycle. Therefore, it is not available at the beginning of the cycle and the branch decision can not be made now.
One more assumption had to be made here to allow the new program counter to be written at this stage. For JALR (jump and link register) and JR (jump register) the pc is getting the value of one of the registers. So, the value has to be read and written at one clock cycle. We assume that it is possible to do so: read on the first half of the cycle and write on the second one.
In order to make pipeline more efficient and to reduce the number of stalls bypassing, or forwarding is used. It works as follows: Before the result is written back to the register file, it can be fed back to the ALU if a later instruction needs it.
The structure used in the simulator to implement bypassing is an array machPtr-->bypass (see Figure 1). It contains the information of all the values available for bypassing. At each execution of WB, MEM or EX stage the corresponding entries are modified. The indicator that a certain element of the array is a valid one is a non-zero value of the stage field. At the end of each cycle these values are set to zero. When a new cycle starts, for each of the stages WB, MEM, EX, if the stage is valid the corresponding entry of machPtr-->bypass is validated and the fields are filled with the necessary values. Later, at the ID stage, after the instruction gets decoded (compiled), the rd (destination register) of all the elements of the bypass array, are compared to the source operands of the instruction. If they match, the next thing to check is whether the appropriate value is already available (to be precise, what is getting checked is whether the value will be available at the beginning of the next cycle). For all instructions except loads, the values are available right away. If the instruction following the load requires its result, this instruction has to stall.
The execution of floating point instructions differs from that of integer ones. The major difference, from the point of view of pipeline implementation, is that the Execute pipe stage takes more than one clock cycle. This requires changes and additions to the general structure of the pipeline simulator. The modifications made to the simulator to manage floating point pipeline are as follows.
When an instruction with floating point operands or result enters the ID stage of pipeline, the function Pipe_FPIssue is called. This function:
The Execute pipe stage for floating point instruction takes more than one clock cycle. When the instruction enters this stage, its result is computed and it is inserted in the list of pending floating point operations Pipe_FPopsList. Besides, this list is checked to find out if any of the operations has completed by this time. If yes, it can be passed to the MEM stage. However, a problem can arise here. Only one instruction with floating point result can enter MEM stage at each clock cycle. So, if there is a one-cycle floating point instruction (e.g. move to floating point register) already in the EX stage, no instruction from the list can proceed. If there are more than one instruction in the list which finish at the same time, only one can proceed, the other ones have to stall. The instruction with the longest latency is given the priority here. At this point one of the hardware assumptions needs to be made also. The prpoblem is as follows: suppose, the result of, say, floating point add is stalled because floating point multiply has finished at the same time and has the priority to go further. Suppose also, that another floating point add is about to start its EX stage. The floating point adder has already finished its job for the first add: the result has been produced. However, it is still at the result latch and may stay there for some time (although more than one stall is very unlikely here, it is still possible under a certain execution pattern). The question is whether to allow the functional unit to start working on the second add or to make it wait until it gets rid of the first result. The decision has been made in favor of the second option. Although it may produce few extra stalls, the situation is very rear and it is not worth it to complicate the control logic in order to avoid these stalls.
An assumption was made that there are separate register files for floating point and integer registers. This assumption allows to have two instructions in MEM or WB stage at the clock cycle, as long as these instructions reference different register files. So, we can say that there are two MEM stages --- MEM and MEM_FP --- and two WB stages --- WB and WB_FP. There are entries in the array machPtr-->stages corresponding to the newly introduced stages: machPtr-->stages[MEM_FP] and machPTr-->stages[WB_FP]. These stages are analyzed in the fashion similar to that of the appropriate integer pipeline stages. The only difference is that a special function is called to write the results back: Pipe_WriteBack. This function writes the result back to a floating point register with the appropriate type casting.
Another design decision which was to be made is about the status of floating point load: whether to consider it as integer or floating point instruction. If we follow the terminology of [1] and consider all loads, no matter integer or fp, to be integer instructions, fp load can overlap with some other floating point instruction in MEM and WB stage. This creates the problem when both instructions reach WB stage and try to write to floating point register file: only one instruction at a time can access the file. So, in fact, load of fp data being considered as integer instruction does not allow any overlapping with fp instructions in the later pipe stages. Another solution is to treat load of fp data as an fp instruction. The way pipeline is implemented now, it does not save anything versus the first solution: other fp instruction still have to stall if they finish the EX stage at the time the load does. However, if the simulator is changed so that MEM stage may take more than one clock cycle (e.g. cache miss), than the second solution allows overlapping of fp load with some integer instruction in case the fp load is stalled. So, our choice was to consider fp load as an fp instruction.
The floating point results can also be forwarded to the earlier pipe stages if needed. The same machPtr-->bypass array is used for this. See Figure 1 for the information on which element of bypass corresponds to the values forwarded from which stage. The necessity of floating point bypassing is checked in the FPIssue function and if the values are needed they are written to the latches. The same problem with the availability of load results and registers for branching arises here: sometime forwarding still can not prevent the necessity of stalls. This is one more case when Pipe_FPIssue may return non-zero value.
There is one more ``pipeline stage'' which as can be seen at Figure 1 and in the program code: DONE (DONE_FP). This is needed only for bookkeeping: to save the information about the instruction which has just finished execution and print out this information if requested by the user with stats pipeline command. The ``stage'' DONE_FP serves for the same purpose for the floating point instructions, since two instructions --- one integer and one floating point --- can finish execution at the same time.
To make DLXsim execute its pipelined version one should call it with -PIPE option:
% dlxsim -PIPE
There is a number of changes and additions made to the user interface of DLXsim session introduced in the manual entry of [2]. This is their description:
When stats is called with the stalls option, number of bypassed values is also reported for the pipelined version of the simulator.
(dlxsim) clear pipeline
It deactivates all pipeline stages and the pipeline becomes empty as in the beginning of the simulation. This might be useful if you want, for example, to start execution of a piece of code as if nothing was executed before it.
Here is an example of interactive session with the pipelined version of DLXsim with the focus on examining pipeline behavior. The program to run is contained in the file example.s and its text follows here:
.global A
A: .double 2
.global B
B: .double 1
.global C
C: .double 17
.align 4
.global _main
_main:
addi r1, r0, A ; store address of vector A in r1
addi r2, r0, B ; store address of vector B in r2
addi r3, r0, C ; store address of vector C in r3
addi r4, r0, #10 ; store the value of x in f0
movi2fp f0, r4
cvti2d f0, f0
ld f2, 0(r1) ;load A
ld f4, 0(r2) ;load B
addd f2, f2, f4 ;A + B
ld f6, 0(r3) ;load C
multd f6, f0, f6 ;x * C
subd f2, f2, f6 ;A + B - x * C
sd 0(r1), f2 ;store into A
trap #0
This program loads three numbers, does some calculations on them and then stores the result. We will show the execution of this code on the pipelined machine. To do that, DLXsim should be called with -PIPE extension:
% dlxsim -PIPE (dlxsim)
Now we can load the program in the DLX memory:
(dlxsim) load example.s
To get the information about the state of the pipeline at any point, one should type stats pipeline (statistics on the pipeline). At the beginning the pipeline is empty:
(dlxsim) stats pipeline
PIPELINE STATE
no instruction starting WB
no instruction starting MEM
no instruction starting EX
no instruction starting ID
no instruction starting IF
The abbreviations are the standard abbreviations adopted in [1]:
Here is the pipeline state after the first step (the step here is always one clock cycle).
(dlxsim) step _main
stopped after single step, pc = _main+0x4: addi r2,r0,0x108
(dlxsim) stats pipeline
PIPELINE STATE
no instruction starting WB
no instruction starting MEM
no instruction starting EX
addi r1,r0,0x100 done with IF and starting ID
addi r2,r0,0x108 starting IF
So, during this clock cycle the first instruction went through its IF stage and will be in ID at the next cycle. The last line shows the instruction which is about to be fetched.
Now we can proceed for few more steps while the instructions proceed through the pipeline.
(dlxsim) step
stopped after single step, pc = _main+0x8: addi r3,r0,0x110
(dlxsim) step
stopped after single step, pc = _main+0xc: addi r4,r0,0xa
(dlxsim) step
stopped after single step, pc = _main+0x10: movi2fp f0,r4
(dlxsim) step
stopped after single step, pc = _main+0x14: cvti2d f0,f0
(dlxsim) stats pipeline
PIPELINE STATE
addi r1,r0,0x100 done with WB
addi r2,r0,0x108 done with MEM and starting WB
addi r3,r0,0x110 done with EX and starting MEM
addi r4,r0,0xa done with ID and starting EX
movi2fp f0,r4 done with IF and starting ID
cvti2d f0,f0 starting IF
(dlxsim) stats stalls
Integer Pipeline Stalls = 0
Floating Point Stalls = 0
Number of bypassed values = 1
All the pipeline stages were busy at the last clock cycle. The first instruction of the program has just completed its execution. Everything was ``smooth'' so far: no stalls; new instruction was fetch at each step. However, there was a necessity to forward one value: the move instruction needs the result of the instruction which is right before it. The result of add is available at the end of its EX stage, so move does not have to stall.
(dlxsim) step
stopped after single step, pc = 0x0: ld f2,0x0(r1)
(dlxsim) step
stopped after single step, pc = 0x0: ld f4,0x0(r2)
(dlxsim) step
stopped after single step, pc = _main+0x20: addd f2,f2,f4
(dlxsim) step
stopped after single step, pc = 0x0: ld f6,0x0(r3)
(dlxsim) stats pipeline
PIPELINE STATE
movi2fp f0,r4 done with WB (fp)
no instruction starting WB
cvti2d f0,f0 done with MEM(fp) and starting WB (fp)
no instruction starting MEM
ld f2,0x0(r1) done with EX (fp) and starting MEM(fp)
ld f4,0x0(r2) done with ID and starting EX
addd f2,f2,f4 done with IF and starting ID
ld f6,0x0(r3) starting IF
Here we had few floating point instructions. All of them were able to get there source operands without stalling, however, bypassing was necessary (for load and convert instructions). One can see here separate pipeline stages for floating point instructions. Information is always given on all integer pipeline stages (even if there is no instruction executing that stage), but for floating point stages only the active ones are mentioned.
One can notice that a pipeline stall will occur at the next step: add cant start its execution because the result from the second load is not ready yet: it will be ready only after MEM stage.
(dlxsim) step
stopped after single step, pc = 0x0: ld f6,0x0(r3)
(dlxsim) stats pipeline
PIPELINE STATE
cvti2d f0,f0 done with WB (fp)
no instruction starting WB
ld f2,0x0(r1) done with MEM(fp) and starting WB (fp)
no instruction starting MEM
ld f4,0x0(r2) done with EX (fp) and starting MEM(fp)
no instruction starting EX
addd f2,f2,f4 done with ID and stalled before EX
ld f6,0x0(r3) done with IF and stalled before ID
As it was expected the pipeline is stalled. The add can proceed only now.
(dlxsim) step
stopped after single step, pc = _main+0x28: multd f6,f0,f6
(dlxsim) step
stopped after single step, pc = _main+0x2c: subd f2,f2,f6
(dlxsim) stats pipeline
PIPELINE STATE
ld f4,0x0(r2) done with WB (fp)
no instruction starting WB
no instruction starting MEM
addd f2,f2,f4 will complete EX in 1 cycle(s)
ld f6,0x0(r3) done with ID and starting EX
multd f6,f0,f6 done with IF and starting ID
subd f2,f2,f6 starting IF
Here is the situation when there are more than one instruction in the EX stage of the pipeline: there are few floating point functional units, so few instruction can execute at the same time. For floating point add it takes more than one cycle to execute, so it is still in the EX stage.
After this cycle two instruction will be done with EX. Both are floating point. So, only one of them can enter MEM stage. The other one has to stall:
(dlxsim) step stopped after single step, pc = _main+0x2c: subd f2,f2,f6 (dlxsim) stats pipeline
PIPELINE STATE
no instruction starting WB
no instruction starting MEM
ld f6,0x0(r3) done with EX (fp) and starting MEM(fp)
addd f2,f2,f4 done with EX (fp) and stalled before MEM(fp)
no instruction starting EX
multd f6,f0,f6 done with ID and stalled before EX
subd f2,f2,f6 done with IF and stalled before ID
The execution will proceed in the same fashion more or less until a trap is received:
(dlxsim) go
TRAP #0 received
(dlxsim) stats pipeline
PIPELINE STATE
no instruction starting WB
no instruction starting MEM
no instruction starting EX
no instruction starting ID
no instruction starting IF
(dlxsim) fget A d
A: 19.000000
So, the pipeline is empty now and the value of A has been modified.
Exercise 1.
This exercise will help you to understand the reasons of pipeline stalls. Consider the following code (it is contained in the file ex1.data):
.global A
A: .double 10
.global B
B: .double 5
.global C
C: .double 2
.global D
D: .double 17
.align 4
.global _main
_main:
addi r1, r0, A
addi r2, r0, B
addi r3, r0, C
addi r4, r0, D
foo:
ld f0, 0(r1)
ld f2, 0(r2)
multd f2, f2, f0
ld f4, 0(r3)
ld f6, 0(r4)
addd f4, f4, f0
subd f6, f6, f0
multd f2, f2, f6
multd f4, f4, f2
sd 0(r3), f4
addi r5, r0, #0
bnez r5, foo
nop
trap #0
This program does simple calculations. Which? What are the pipeline
stalls occurring here? Trace the execution of the program using the
simulator and explain the reasons for all the stalls in it.
Exercise 2.
Do the exercise 4.14 (a and b) from the textbook. You may use the DLXsim to collect the data and to try various ordering of instructions to maximize performance.