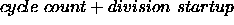 , we can stop scanning
through the list. After this VectWriteBack returns.
, we can stop scanning
through the list. After this VectWriteBack returns.
This project involved extending the DLXsim, the simulator written in the University of California at Berkeley, to incorporate the simulation of a vector machine. The vector architecture simulated is the DLXV architecture described in Computer Architecture, A Quantitative Approach by Hennessy and Patterson ([1]). The DLXVsim (the DLXV architecture simulator) uses the same user interface as DLXsim described in [2], augmented by few more commands to examine vector machine behavior. When extending the DLXsim there were two major tasks to consider: creating and operating on the data structures for vector architecture simulation and extending the instruction set already implemented in DLXsim. These two issues will be addressed in this report along with the description of the machine simulated and the design decisions and assumptions made. This will be followed by some examples of how to use the simulator. We expect that a major use of this tool will be in Computer Architecture classes to help in understanding of vector architecture. Few sample exercises that can be used in these classes, may be found at the end of this report.
The DLXV architecture simulated is basically the one described in [1]. The major characteristics of the DLXV architecture are as follows.
The DLXVsim supports all the instructions described in [1]. All the instructions work on double-precision floating point numbers.
The DLXsim simulator gives you the opportunity to extend the standard instruction set. Obviously, this had to be done in order to incorporate vector machine simulator. There are few details one should consider when extending the instruction set. Here is the pattern which may be followed when doing that.
File sim.c contains instruction tables with information about DLX instruction set. The first is opTable. It contains entries corresponding to possible opCodes. Each entry consists of the opCode itself and the type of the instruction: I-type, R-type or J-type. (See [1] for the description of these types). Several entries in the table have the opcode OP_RES and are reserved for new instructions. So, if you want to have a new instruction in the instruction set, you put its opcode instead of any OP_RES. Be careful not to change the existing order of instructions if you do not want to encounter unnecessary complications with assembling the DLX code.
All the register-register instruction have one of the following two opcodes in this table: SPECIAL or FPARITH corresponding to integer and floating point operations. These opcodes indicate that another table should be used to identify the instruction. The tables are specialTable and FParithTable correspondingly. All the vector instructions have VECTARITH opcode in the opTable. This was done because all the vector instructions in DLXV are register-register ones and we decided to follow the idea of separating each class of the R-type instruction in a different table. This allows identifying all the vector instructions just by one opcode and also reserves space for up to 64 vector operations.
There is one more table (operationNames) which is used to print out the names of the instructions when the dynamic instruction count is requested. It contains the alphabetic list of all integer instructions, followed by floating point instructions, followed by vector instructions. The instruction index in this table should be equal to the number corresponding to each opCode as defined in the #define statements in the dlx.h file. So when modifying one (the table or the definitions) do not forget to modify the other.
New instructions need to be assembled and disassembled when they appear in the source file. The procedures for doing that are contained in the asm.c file. This file also contains the information about all opcodes in the opcodes table. New entries describing new instructions should be added to this table. The following comments might be useful when you want to do that.
Some changes in the lexical analizer are also required to parse new types of instructions and delimiters.
The last and, probably, the most obvious change needed, is to add new cases to the very large switch statement in Simulate function. These cases should contain the implementation of the instruction itself. Here the semantics of the instruction is considered and the corresponding actions implied from it, are simulated. All the vector ``cases'' call the corresponding functions from the vect.c file. The description of these functions follows in the next section.
Data structures and execution control for vectors are similar to those for floating point data structures and control implemented in DLXsim .
The vector variables and data structures are all declared in the file dlx.h. The variables are the fields of the DLX structure describing the state of the machine.
Each vector register is simulated by an array of 1024 double-precision floating point numbers which is defined as type VR. To simulate vector registers of the smaller length, field mvl (maximum vector length) in DLX structure is used. The default value of this parameter is 64. Pointers to the content of all the register are in the array variable VRegs.
Five units operate on vectors in DLXV: add/subtract, divide, multiply, load/store and compare. For each type of the functional units there is:
The arrays described in the last item are accessed via the array of pointers vect_units.
For efficient operation of the vector machine two special registers are required: vector-mask register and vector-length register. (See [1] for detailed description of their use.) The value of the vector length register is stored in the VLR variable. The vector-mask register is an array of bytes pointed by VM where the number of bits is equal to the maximum vector length. Therefore, each bit corresponds to each element of the vector. The value of variable VM_Loaded indicates if this vector has been loaded and should be taken into consideration or not.
There are two arrays used for vector data hazard detection: waiting_VectRs and being_read_VectRs. A non-zero value in the former one means that the corresponding vector is waiting for the result and the value is the clock cycle when this result is being written. The second array is needed because of the following feature of the vector operations: when the instruction starts its execution, during the first 64 cycles (or whatever the vector length is) the values are fed from the register to the vector unit. Although the instruction is not completed at this point, the source vector register values are not needed any more and the register can become available for writing. So, if any instruction is stalled to prevent WAR hazard, it can be issued now. The non-zero value in the array being_read_VectRs is the clock cycle when the register becomes available for writing. There is one extra element in each of the arrays to keep track of the status of the vector-mask register.
The list VectOpsList is very similar to the list FPopsList used for floating point operations (see [2]). It is a linked list of structures of type Vectop, where each element contains all the information needed about pending vector operation. The first element of the list is the instruction which will finish first, followed by the one that will finish second, and so on.
Before each vector operation can start its execution, it needs to be issued. So, from each switch case for vector instructions in the vect.c file, VectIssue is called. This function detects if there are any data or structural hazards. It checks for the availability of appropriate registers for reading or writing and availability of the corresponding functional units. If any hazard occurs and the instruction needs to be stalled, VectIssue returns the number of clock cycles it needs to be stalled for. Otherwise, the return value is zero and the appropriate entry in the VectopsList is created. The results are computed at this stage and the values in the appropriate controlling data structures are modified.
Since all the vector operations are different in terms of type of registers used (vector, floating point or general purpose registers), functional units needed, types of results returned, the number of different flags are passed to this procedure to ensure that all hazards are detected correctly and at the same time no extra stalls are inserted.
The first thing to check here is the vector-mask register. It is used for all the instructions so it is better to start with it. If it is in the process of being loaded, no other instruction can be issued.
If the destination register of the new instruction is at the same time a source operand of the instruction already in execution, the new one has to stall before that register will be read and, therefore, will become available for writing. If it is being written, more stalls are needed to wait when the writing is finished. The only thing to care about for the source operands is that they are not being written. If yes, stall also.
There is a number of vector instructions which take only one clock cycle to execute. These instructions do not use any of the vector functional units and do not need to be recorded in VectOpsList. These are moves from fp registers to vector-mask register and vice-versa (MOVF2S and MOVS2I). The choice has been made to make CVM (set vector-mask register) and POP (count the number of 1's in the vector-mask register) execute in one clock cycle as well. For the first one resetting the whole vector-mask is not necessary: it is sufficient just to change the value of the flag which indicates whether the register is loaded or not. There is more ``action'' necessary to execute POP, but if it takes more than 1 cycle to complete, then we will have such thing as ``pending operation with the integer result'' and this one will be the only one of this kind. Firstly, it will only complicate the things: separate structure for this kind of instructions will be needed and checking for hazards before issuing any instruction (integer, fp, vector) becomes necessary. Secondly, if we want to make it possible to execute POP in one cycle, the extra hardware needed for that is not that difficult. So, the choice has been made towards one-cycle execution.
The structural hazard detection is very similar for that of floating-point arithmetic. It forces the instruction to stall if the functional unit is not available. Since all the vector functional units are fully pipelined, the condition to check is: is the first stage of the unit pipeline empty or not?
If the instruction has been successfully issued, its result is computed, and the new entry is inserted in the VectopsList. When the value is being computed, the vector-mask register and vector-length register values are taken into consideration. For the store operations the values are written in the DLX memory at this stage. For all others, the destination registers are not being modified here: this will be done later in the VectWriteBack when the number of clock cycles needed to complete the instruction elapses.
Each time when the counter of the clock cycles is incremented, the VectWriteBack function is called. It scans through the list of the pending vector operations, and if some of the instructions have finished by this time, it writes the
new values in the destination registers and resets the values in the hazard
control structures. The instructions which have finished are at the beginning
of the list, so there is no necessity to go through the whole list to find them. However, some instructions can just finish reading the source operands by
this time and this also needs to be reflected in the control structures:
the appropriate values in the being_read_VectRs array should be reset
and the functional units should become available for incoming instructions.
The list is not ordered with respect to the value of the read field,
but it is easy to note that the maximum difference between ready and
read values is the maximum possible startup cost (which is obviously
the one for the vector division). Therefore, once the read values
become more than , we can stop scanning
through the list. After this VectWriteBack returns.
When writing the vector machine simulator, the necessity of one more instruction came up. This instruction is not included in the vector instruction set of DLXV, however, it appears to be useful. It is a synchronizing instruction sync which is equivalent to as many nops as necessary to complete all the operations in execution at that moment. The reason for doing this is as follows.
When the control is passed to the operating system by trap, there still could be pending floating point and vector operations. This situation is much more frequent for vector case because of the long latency of all vector instructions. So, to have the results ready by the time the control is passed to the operating system, certain number of stalls should be inserted. The sync instruction does it. It goes through the lists of pending floating point and vector operations, finds the one which takes the longest time to complete and sets the cycle count to that cycle when it will be ready.
Hardware implementation of this instruction does not seem to be very costly. The only thing needed is some circuitry to check if any of the functional units is busy, and if yes, insert stalls.
As far as the simulator is concerned, the process of finding the last instruction is easy because the lists of instructions in execution are ordered with respect to the cycle when they will be ready.
Few more commands were added to the user interface of DLXsim (see manual entry of [2]). These are the commands to specify vector hardware features, examine content of vectors, get the information on the vector instructions in execution.
To make DLXsim to be a vector machine simulator (DLXVsim) one should call it with -VECTOR option:
% dlxsim -VECTOR
DLXVsim can be called with the number of parameters such as number of vector functional units, their startup costs, maximum vector length and the number of vector registers. The vector options of the dlxsim command are the following:
Vectors located in the DLX memory can be accessed by the fget and fput commands provided by DLXsim. However, this commands do not give the access to vector registers. To do that and also to address vectors in memory in the vector-oriented style (with index), one can use the following DLXVsim commands:
Some of the options of the stats (dump statistics) command of the simulator were revised to incorporate the information of the vector machine behavior. One new option has been added to examine the vector hardware configuration. Here is the list of the stats options which were changed as compared to the DLXsim:
The next section gives an example of an interactive session with DLXVsim.
Here is an example of the interactive session with the DLXVsim. We will consider the following simple program written in the DLXV assembly language:
.data 0
.global A
A: .double 1, 2, 3, 4, 5, 6, 7, 8
.global B
B: .double 1, 0, 1, 0, 1, 0, 1, 0
_main:
cvm ; clear vector mask register
addi r1, r0, A ; store the address of A in r1
addi r2, r0, B ; store the address of B in r2
lv v1, r1 ; load vector A in v1
lv v2, r2 ; load vector B in v2
addv v1, v1, v2 ; A = A + B
sv r1, v1 ; store v1 in A
sync ; synchronize
trap #0 ; pass the control to operating system
As one can see, this program takes the two vectors, adds them and stores the result in the first one.
The observation that can be made is that the vector length is only 8 numbers, so the parameter specifying the vector length can be used when calling DLXVsim :
% dlxsim -VECTOR -mvl8 (dlxsim)
Now the code should be loaded. It is contained in the file example.s
(dlxsim) load example.s
Here is the vector hardware configuration for the machine which is being simulated:
(dlxsim) stats vhw Memory size: 65536 bytes. Vector Hardware Configuration 8 vector registers 8 is the maximum vector length 1 add/subtract unit(s), startup cost = 6 cycles 1 multiply unit(s), startup cost = 7 cycles 1 divide unit(s), startup cost = 20 cycles 1 comparison unit(s), startup cost = 6 cycles 1 load/store unit(s), startup cost = 12 cycles
That is, all the parameters except the maximum vector length are the default values of the machine.
Now we can start step-by-step execution to display the abilities of the simulator.
(dlxsim) step _main stopped after single step, pc = _main+0x4: addi r1,r0,0x0 (dlxsim) step stopped after single step, pc = _main+0x8: addi r2,r0,0x40 (dlxsim) step stopped after single step, pc = _main+0xc: lv v1,r1
So, r1 now contains the address of A, r2 -- the address of B and vector load can be started now. There are no pending vector operations so far:
(dlxsim) stats pending Pending Floating Point Operations: none. Pending Vector Operations: none.
Nothing prevents the load from issuing: the load/store unit is unused and the source general-purpose register (r1) is available.
(dlxsim) step stopped after single step, pc = _main+0x10: lv v2,r2 (dlxsim) stats stalls pending Load Stalls = 0 Floating Point Stalls = 0 Vector Stalls = 0 Pending Floating Point Operations: none. Pending Vector Operations: loader #1 : will complete in 19 more cycle(s) ==> v1
The last line shows that the loader number 1 (in fact, the only one in our machine) will complete its work in 19 clock cycles:
The result from the loader goes to the vector register v1.
There were no stalls so far. But now we need to issue one more vector load. However, only one load/store unit is available, so stalls occur before it is issued.
(dlxsim) step stopped after single step, pc = _main+0x14: addv v1,v1,v2 (dlxsim) stats stalls Load Stalls = 0 Floating Point Stalls = 0 Vector Stalls = 7
There were only 7 stalls because by this time all the elements of vector A are already fed in the load unit and the unit can take new values on the next clock cycle. Now the loader is working on the two instructions simultaneously:
(dlxsim) stats pending Pending Floating Point Operations: none. Pending Vector Operations: loader #1 : will complete in 11 more cycle(s) ==> v1 loader #1 : will complete in 23 more cycle(s) ==> v2
The second load takes more time than the first one (24 vs. 20) because of the 4 clock-cycle instruction dependence penalty. And more stalls are needed now: addv cannot issue before both loads complete, because addition requires both vectors.
(dlxsim) step stopped after single step, pc = _main+0x18: sv r1,v1 Load Stalls = 0 Floating Point Stalls = 0 Vector Stalls = 30 Pending Floating Point Operations: none. Pending Vector Operations: adder #1 : will complete in 17 more cycle(s) ==> v1 ( register(s) v1 v2 will be read in 11 more cycles )
Since the addition is not finished yet, the register v1 should contain vector A. It can be examined now and we will do one more step after that.
(dlxsim) vget v1[0..7] v1[0] : 1.000000 v1[1] : 2.000000 v1[2] : 3.000000 v1[3] : 4.000000 v1[4] : 5.000000 v1[5] : 6.000000 v1[6] : 7.000000 v1[7] : 8.000000 (dlxsim) step stopped after single step, pc = _main+0x1c: sync (dlxsim) stats pending Pending Floating Point Operations: none. Pending Vector Operations: loader #1 : will complete in 23 more cycle(s) ( register(s) v1 will be read in 11 more cycles )
The instruction which will execute next (sync) will insert the number of vector stalls necessary to complete the pending store operation.
(dlxsim) step stopped after single step, pc = _main+0x20: trap 0x0 (dlxsim) stats stalls pending Load Stalls = 0 Floating Point Stalls = 0 Vector Stalls = 70 Pending Floating Point Operations: none. Pending Vector Operations: none.
And to finish:
(dlxsim) step TRAP #0 received (dlxsim) vget A[0..2] A[0] : 2.000000 A[1] : 2.000000 A[2] : 4.000000
The values of the elements of vector A have been modified.
One could notice the big number of stalls in this example. The vector machine does not look very efficient here. This is the reason why various refinements are used to improve the performance: vector-mask capability, load/store with stride or with index. The influence of these improvements can be explored by using this simulator. All the instructions described in [1] can be used in the assembly codes to be run on the simulator. For better understanding of the details of vector architecture and DLXV instruction set, the exercises after this section can be used.
Exercise 1.
Consider the following code.
for (i = 0; i < 64; i++) {
A[i] = A[i] / B[i] + x * C[i]
}
Exercise 2.
In this exercise you will see how different hardware parameters can effect performance of the machine.
The DLXV simulator has default hardware parameters as described in [1]. That is by examining configuration of the machine you will see the following:
dlxsim % dlxsim
(dlxsim) stats vhw
Memory size: 65536 bytes.
Vector Hardware Configuration
8 vector registers
64 is the maximum vector length
1 add/subtract unit(s), startup cost = 6 cycles
1 multiply unit(s), startup cost = 7 cycles
1 divide unit(s), startup cost = 20 cycles
1 comparison unit(s), startup cost = 6 cycles
1 load/store unit(s), startup cost = 12 cycles
However, you may change this configuration. In this case, you should be aware that by increasing the number of functional units, you may increase the corresponding startup cost. Make your assumptions of how much this cost is increased. For example, reasonable assumptions may be as follows: with the addition of each new load/store unit, the startup cost is increased by 30%, and the same number for the vector add unit maybe 5%
Now consider the following DLXV code (you will find it in the file ex2.data):
.text 0x800 addi r1, r0, A ; store address of vector A in r1 addi r2, r0, B ; store address of vector B in r2 addi r3, r0, C ; store address of vector C in r3 lv v1, r1 ; load A lv v2, r2 ; load B lv v3, r3 ; load C addv v1, v1, v2 ; A = A + B sv r1, v1 ; store A addsv v3, f0, v3 ; C = 10 + C addv v3, v1, v3 ; C = A + C sv r3, v3 ; store C sync ; complete all the pending operations trap #0Note: consider that each vector has 16 elements
Find the hardware configuration which results in the least number of clock cycles for this code. Read the DLXV manual to see which parameters you can alter.
Explain, why adding more functional units even with the small increase of startup costs may not be profitable. Do you think it is a typical situation? Why?
Try to optimize this code considering the original DLXV configuration.
Exercise 3.
Consider the following code.
for (i = 0; i < 64; i++) {
if (B[i] != 0)
B[i] = A[i] + B[i]
}