Load Balancing a Cluster of Web Servers
Using
Distributed Packet Rewriting
Technical Project Report
| Luis Aversa | Azer Bestavros |
| laversa@cs.bu.edu | best@cs.bu.edu |
Commonwealth Project Group
Computer Science Department
Boston University
Abstract:
1. Introduction
In recent years, global use of the Web has become ever more ubiquitous among the general population. The millions of hits received daily by web servers have increased exponentially year by year, as has hardware capacity to allow users to access the Web at higher speeds. In order to meet the demands these factors have placed on the World Wide Web, one must address the issue of how web servers handle the load that they are exposed to.
Distributed systems have become a viable solution to manage this increased growth of traffic on the World Wide Web. Spreading the workload among a cluster of servers as opposed to a single machine handling all of the requests is a logical approach to the problem. A number of designs have been proposed that incorporate this concept. TCP routing is one such technique that uses distributed technology to re-route requests to a number of servers to increase overall capacity for a single IP address. A single machine whose IP address is published in the DNS server takes all incoming requests and distributes them among the cluster of servers (see Dias et al 1996 and Cisco Local Director 1997 for examples). However, this design does not take into account the fact that the machine re-routing all requests becomes a bottleneck at high loads. A proposed alternative to this centralized approach is Distributed Packet Rewriting (see Bestavros et al 1998)(DPR).
DPR follows the same idea of distributing requests among a number of web servers to handle high loads of web traffic. The major difference between DPR and TCP routing lies in the manner in which IP addresses are published. DPR uses Round-Robin DNS to publish individual addresses of all machines in the cluster of web servers, thereby distributing the responsibility of re-routing requests to each machine. In this paper, we show that this decentralized approach is far more effective in handling high loads of web traffic than the previously proposed centralized approach.
2. Distributed Packet Rewriting
In the implementation of DPR, each machine within the cluster provides
web service, along with the ability to re-route requests to other machines.
All machines IP addresses are published, allowing any of the machines
to receive requests. These requests then can be either served locally or
re-routed to another machine. In the later case, the responsibility of
serving the request will be transferred to another machine, which will
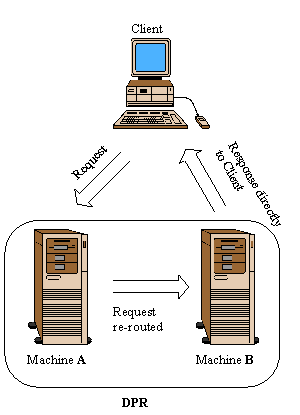
respond directly to the client. Suppose that machine A (see figure below)
receives the original request from client C. Machine A re-routes the request
to machine B. Machine B will subsequently serve the request to client C,
using the IP address of machine A as the source IP, effectively masking
the process of re-routing the request from machine A to machine B. Client
C will continue to send packets to machine A, unaware of the fact that
the request had been forwarded to machine B.
In this implementation, it is necessary for the machines within
the cluster of servers to be able to distinguish between packets that have
been re-routed and packets that come directly from the client. Furthermore,
if machine A re-routed a request to machine B, machine A must somehow let
machine B know client Cs IP address in order to respond to the request.
One of the techniques in which this is accomplished is IP-IP.
Using IP-IP, machine A can encapsulate the original packet received from client C inside another IP packet, which is then re-routed to machine B. Machine B is now able to deduce the packet was re-routed by machine A, and can respond to client C accordingly. It can also find the source IP of client C within the encapsulated packet in order to complete the request. If machine A receives an IP-IP packet from another machine within the cluster (machine B), machine A will know that the request had been re-routed from machine B and had not come directly from the client. Using this information, machine B is able to complete processing the request to client C.
DPR was originally tested using a randomized algorithm to determine whether or not to forward packets or serve them locally. Based on a hash function that was applied to the source port number of the TCP packet, the decision was made. This approach is entirely stateless it does not rely on feedback from other machines regarding current load in order to make the determination of whether to forward a packet. We argue that using a stateful approach to distribute packets will achieve better throughput and a faster mean response time to the client.
3. Implementation
In this section, we will describe the stateful implementation, using an algorithm to balance the load to enhance the DPR functionality in distributing requests. Each machine internally keeps an updated list of all other machines within the cluster, with information such as their IP addresses and current load. Hosts intermittently broadcast their load to the other machines, which is then used to determine whether or not to re-route requests or serve them locally. Also, each machine will keep routing tables with information about redirected connections. When a new request is received by machine A from client C, machine A first examines its own load. If it is under a certain threshold value, it will serve the request locally. If not, it will create a new entry on the routing tables and forward the request to the machine that currently has the lowest load to avoid thrashing. This threshold value can be adjusted according to certain factors such as CPU speed, memory, etc.
Various ways of measuring the load were applied and the best results were obtained using the number of current open TCP connections each machine has at any given moment. Another load values were applied, such as CPU utilization, number of redirected TCP connections, active sockets and factors obtained as a combination of these values, but none of them performed better than the plain value of open TCP connections.
The implementation of the stateful approach was completed in two stages
using linux 2.0.28 as operating system. The first phase was to design a
very fast mechanism to search, insert, delete and update real-time data
for re-routing purposes. This mechanism was implemented entirely in the
kernel using multiples hash table and linked list. The second phase was
to design a mechanism to store the information regarding other machines
current loads and update it every second to determine whether or not to
forward requests to the machine with the lowest load or serve them internally.
A sorted linked list, Three user processes and new systems calls were needed
for the implementation of this phase.
3.1. Routing Tables
The mechanism to redirect connections was implemented in the kernel for performance reasons. It is very important to be fast when deciding to redirect or serve a new connection and when forwarding incoming packets of connections that have been redirected.
When a machine receives an IP packet, the kernel calls the function ip_receive(). Some modifications were made to this function to be able to redirect connections. In this function, the IP packet is examined. If it contains a TCP packet and the TCP destination port is 80 (or where the web server is running), we know that it is an http connection and is coming directly from the client. If the TCP packet contains a SYN, then we know a new connection have been requested. A decision has to be made, to serve it or to forward it. The decision is base on the load table and the current load of the machine. If the machine is under the threshold value or the current load of the machine is the lowest compared with the others machines then the request is served locally and no routing tables are updated. If the current load is over the threshold value and the lowest load correspond to another machine then the routing tables are updated and the packet is forwarded. If the packet is not a SYN then, we look up in the tables and if the connection has been redirected, then the packet is forwarded. If the IP packet contains an IP-IP packet and the unused bit of the fragment offset is set to 1, we know that it is a packet that has been redirected and we have to serve it. We unpack the IP-IP packet and send the TCP packet to the TCP layer to be processed. Instead of utilizing the unused bit of the fragment offset, we could check if the source IP address correspond to the servers participating in the DPR to detect redirected connections.
The modifications to ip_input.c can be seen
in ip_receive(). Three new files were added
to the kernel to implement the look up tables and load tables, dprsocketcall.h,
dpr.h,
dpr.c.
3.2. Load information
The mechanism to update the load was implemented with three user processes and seven new system calls. One process is in charge of broadcasting its own load every second. To get its own load information, it makes a system call to obtain the appropriate value of the load. A second process is waiting for the load of the other servers that are participation in the DPR. Every time a new value is received, the process makes a system call to update the sorted linked list that is in the kernel. The third process is in charge of cleaning up of the load and routing tables. If no load packet is received from one machine for a certain number of second, then the entry of this machine in the load table is deleted to avoid redirecting connection to a machine that is not running.
Using IP-IP to redirect connections allows us to have servers in different networks. We only need to tell the process in charge of broadcasting the load the networks that participate in the DPR. If more than one network have servers participating in the DPR, this process will broadcast the load packet not only to the local network but also to all the other ones defined in the webnetip.txt file. The implementation of the user process can be seen in, load_balance.h, load_balance.c
Seven new system calls were implement to access and update the kernel memory
DprUserInit.c : To initialize the DPR
DprGetLoad.c : To get the current load of the server.
DprSetLoad.c : To update the load of the servers participating in the DPR.
DprSetNetIp.c : To update all the networks participating in the DPR.
DprGetNetLoad.c : To get all the networks participating in the DPR
DprCleanUp.c: To clean up memory in the kernel
DprSetHashIp.c: To define the IP address of the machine participating in the random DPR
The implementation of the system call can be seen in, socket.c, sys_socketcall(), and dpr.c
4. Measuring procedures
In order to evaluate the performance and the load distribution of the implementation, we used a URL request generator tool, or SURGE (see Barford and Crovella 1998) (Scalable URL Reference Generator) to create a realistic web workload. Surge was run in each client machine with the following parameters: five client sub-processes with 50 thread each for 200 seconds. We ran SURGE from six machines that were generating requests to three web servers. The servers were running apache on brookline, baystate and buick. Four SURGE clients were generating requests to buick, one to brookline and one baystate as shown in figure below.
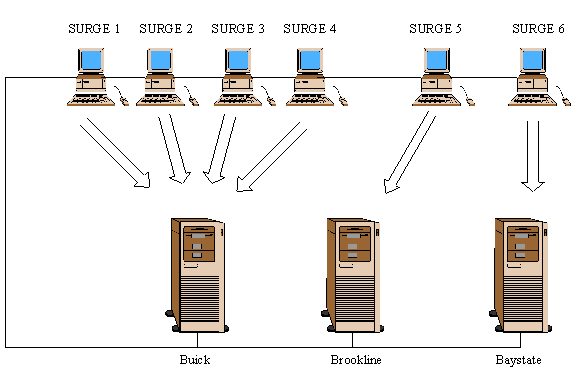
This configuration produces a heavy load to one of the machines. This is what usually happens when we use round-robin DNS. We show in the next section the behavior of the cluster applying different algorithms to balance the load. First, we ran the test using not load balancing at all, second we used the random load balancing and third, we used the TCP load balancing algorithm explained in the implementation section.
5. Results
As we can see in the table, using TCP load balancing we obtain a better
mean transfer delay and a larger number of requests served per second.
The mean transfer delay is the expected service time for http requests.
| Method used |
|
|
|
|
| No Load Balancing |
0.918775
|
15.240973
|
96,726.00
|
496.03
|
| Random Load Balancing |
0.372362
|
0.813577
|
123,798.00
|
634.86
|
| TCP Load Balancing |
0.263267
|
0.85949
|
129,278.00
|
662.96
|
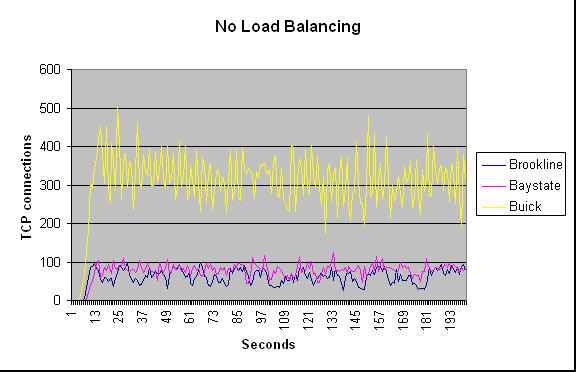
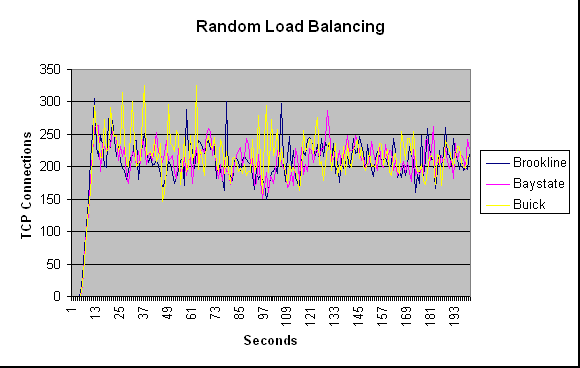
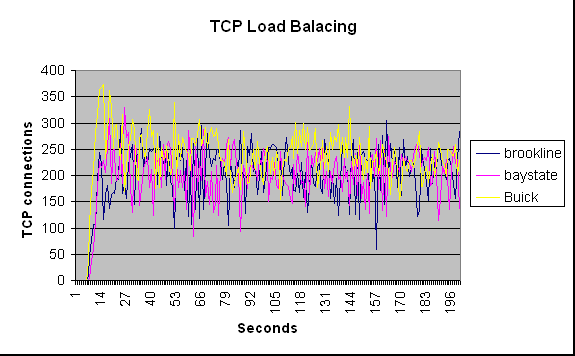
The following three graphs show the behavior of the cluster with the
three different methods used. They show how many connections each machine
serves per second. When we use no load balancing, we can see that majority
of requests were served by buick. When we use Random load balancing or
TCP load balancing we can see the three servers are serving approximately
the same number of connections per second leading to a better response
time and throughput.
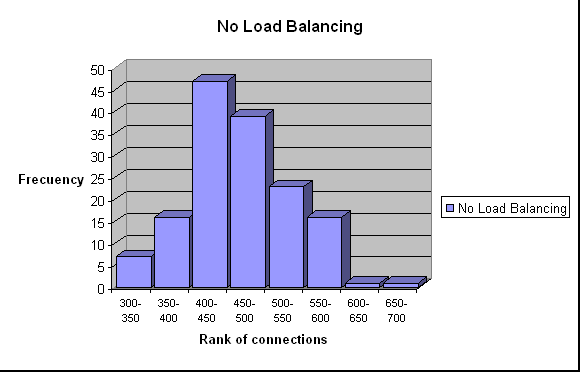
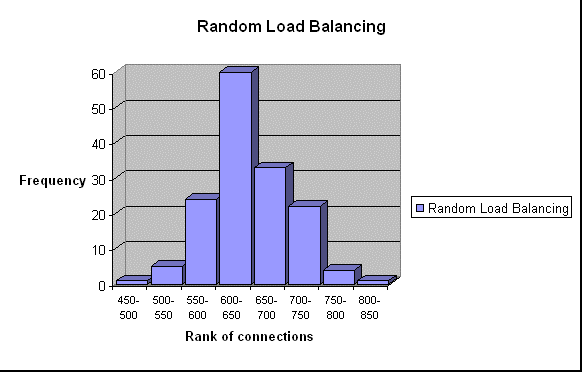
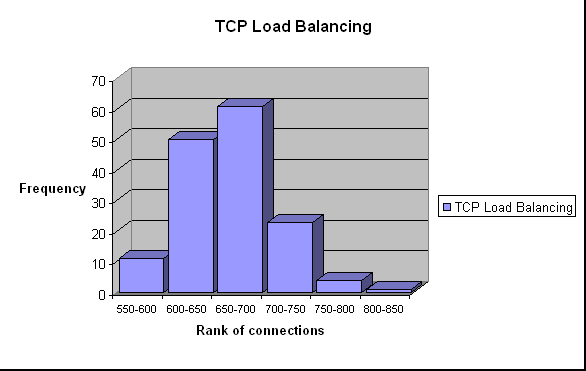
These graphs show the number of observations per ranks of total connections
served by the cluster.
| Method |
|
|
|
|
| No Load Balancing |
462
|
372
|
557
|
1.2
|
| Random Load Balancing |
643
|
573
|
722
|
1.16
|
| TCP Load Balancing |
660
|
605
|
717
|
1.08
|
References
Acknoweldgments: We would like to thank all members of the Commonwealth Research Group for their support and for the many useful discussions that helped solidify the results presented in this report. In particular, we would like to acknowledge the help of Mark Crovella, David Martin, Jun Liu, Jorge Londono, and Paul Barford. This work was partially supported by NSF research grant CCR-9706685 and by Microsoft.
Note: The source code referenced in this report is available to members of the Commonwealth Research Group. For access, please contact the authors.