Problem Set 8
due by 11:59 p.m. Eastern time on Wednesday, April 29, 2026
No submissions will be accepted after Wednesday, April 29th
Preliminaries
In your work on this assignment, make sure to abide by the collaboration policies of the course.
If you have questions while working on this assignment, please
come to office hours, post them on Piazza, or email
cs112-staff@cs.bu.edu.
Make sure to submit your work following the instructions found at the end of the assignment.
Part I
55 points total
Creating the necessary file
Problems in Part I will be completed in a single PDF file. To create it, you should do the following:
-
Open the template that we have created for these problems in Google Docs: ps8_partI
-
Select File->Make a copy..., and save the copy to your Google Drive using the name
ps8_partI. -
Add your work to this file.
-
Once you have completed all of these problems, choose File->Download->PDF document, and save the PDF file on your machine. The resulting PDF file (
ps8_partI.pdf) is the one that you will submit. See the submission guidelines at the end of Part I.
Problem 1: Checking for keys above a value
10 points total; individual-only
The code below represents one algorithm for determining if there are
any keys greater than a given value v in an instance of our
LinkedTree class. The anyGreaterInTree() method returns true if
there are any keys greater than v in the tree/subtree whose root
node is specified by the first parameter of the method, and it returns
false if there are no such keys. The anyGreater() method returns
true if there are any keys greater than v in the entire tree
represented by the LinkedTree object on which the method is invoked
and false otherwise.
public boolean anyGreater(int v) { // make the first call to the recursive method, // passing in the root of the tree as a whole return anyGreaterInTree(root, v); } private static boolean anyGreaterInTree(Node root, int v) { if (root == null) { return false; } else { boolean anyGreaterInLeft = anyGreaterInTree(root.left, v); boolean anyGreaterInRight = anyGreaterInTree(root.right, v); return (root.key > v || anyGreaterInLeft || anyGreaterInRight); } }
-
For a binary tree with n nodes, what is the time efficiency of this algorithm as a function of n? Use big-O notation, and explain your answer briefly.
If the time efficiency depends on the keys in the tree or on the tree’s shape, you should explain why and give three big-O expressions: one for the best case, one for the worst case if the tree is balanced, and one for the worst case if the tree is not balanced. If the time efficiency does not depend on the keys or the shape of the tree, you should explain why and give one big-O expression.
-
If the tree is a binary search tree, we can revise the algorithm to take advantage of the ways in which the keys are arranged in the tree. Write a revised version of
anyGreaterInTreethat does so. Your new method should avoid visiting nodes unnecessarily. In the same way that the search for a key doesn’t consider every node in the tree, your method should avoid considering subtrees that aren’t needed to determine the correct return value. Like the original version of the method above, your revised method should also be recursive.Note: In the files that we’ve given you for Part II, the
LinkedTreeclass includes the methods shown above. Feel free to replace the originalanyGreaterInTree()method with your new version so that you can test its correctness. However, your new version of the method should ultimately be included in your copy ofps8_partI. -
For a binary search tree with n nodes, what is the time efficiency of your revised algorithm as a function of n?
Here again, if the time efficiency depends on the keys in the tree or on the tree’s shape, you should explain why and give three big-O expressions: one for the best case, one for the worst case if the tree is balanced, and one for the worst case if the tree is not balanced. If the time efficiency does not depend on the keys or the shape of the tree, you should explain why and give one big-O expression.
Problem 2: Balanced search trees revisted
5 points; individual-only
Illustrate the process of inserting the key sequence
V, C, M, F, K, H, P, Y, S, J
into an initially empty 2-3 tree. Show the tree after each insertion that causes a split of one or more nodes, and the final tree.
We have given you a sample diagram that includes nodes of different sizes. Make copies of the diagram so that you can use separate diagrams for the results of each insertion that causes a split, and for the final tree. Note that you do not need to keep the shape of the tree that we have given you. Rather, you should edit it as needed: deleting or adding nodes and edges, replacing the Xs with keys, adding or removing keys, and making whatever other changes are needed.
Problem 3: Comparing data structures
5 points total; individual-only
A university wants you to implement an in-memory database that can be used to access information about their courses. Although a snapshot of this database will be periodically copied to disk, its contents fit in memory, and your component of the application will operate only on data stored in memory.
Here are the requirements specified by the university registrar:
-
They want to be able to retrieve course records by specifying the course name, which consists of the departmental abbreviation followed by the course number (e.g., “CS112” or “MA121”).
-
They want the time required to retrieve a record to relatively efficient – on the order of 15-20 operations per retrieval, given a database of approximately 20,000 records.
-
They want to be able to efficiently retrieve all courses for a given department (e.g., all CS courses)
-
They want to be able to add the records for the upcoming semester – adding a large set of new records – without taking the system offline.
Given this list of requirements, which of the following data structures would be the best choice for this application:
- a binary search tree
- a 2-3 tree
- a hash table.
Explain your decision, specifying as many reasons as possible for the choice that you make.
Problem 4: Complete trees and arrays
9 pts. total; individual-only
Assume that you have a complete tree with 325 nodes, and that you represent it in array form.
-
Node A of the tree is in position 75 of the array. What are the indices of A’s left child, right child, and parent? Explain how you got your answers.
-
What is the height of the tree? Explain your answer briefly.
-
The bottom level of the tree contains some number of leaf nodes. Is the rightmost leaf node in the bottom level the left child of its parent or the right child of its parent? Explain your answer briefly.
Problem 5: Heaps
8 pts. total; individual-only
Consider the following heap of integers:
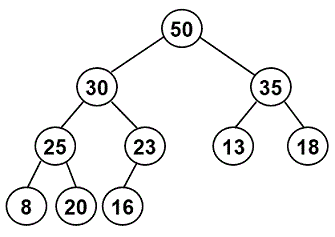
-
Show the heap as it will appear:
-
after one removal (i.e., after one call to the
remove()method discussed in lecture) -
after a second removal.
You should include two separate diagrams, one for how the heap will look after each removal. To do so, you should:
-
Edit the diagram provided in section 5-1 of
ps8_partIby clicking on it and then clicking the Edit link that appears below the diagram. -
Make the necessary changes to the tree to show the results of the first removal.
-
Click the Save & Close button.
-
Make a copy of your edited diagram within the Google Doc and edit it to show the results of the second removal.
-
-
Suppose we have the original heap and that 40 is inserted followed by 75. Show the final heap by editing the diagram that we have provided in section 5-2 of
ps8_partI.
Problem 6: Heaps and heapsort
8 pts. total; individual-only
Consider the following complete tree of integers:
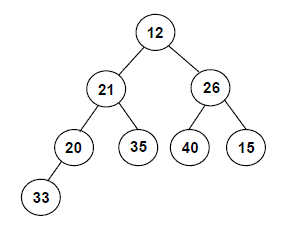
-
Turn this tree into a max-at-top heap using the procedure outlined in lecture, and show the heap that is produced.
-
Edit the diagram provided in section 6-1 of
ps8_partIby clicking on it and then clicking the Edit link that appears below the diagram. -
Make the necessary changes to the tree to show the final heap.
-
-
What is the array representation of the max-at-top heap that you obtained in part 1?
-
Heapsort begins by turning the array to be sorted into a heap. Assume that your answer to part 2 is the result of this process of turning the original array into a heap.
What will the array look like after one element is put into its final position by heapsort – i.e., at the end of the first iteration of the loop in
heapSort()?What will the array look like after the second element is put into its final position?
Problem 7: Hash tables
10 points total; individual-only
The following sequence of keys is to be inserted into an initially empty hash table of size 8 that employs open addressing:
the, my, an, by, do, we, if, to, go
The hash function assigns to each key the number of characters in the
key. For example, h("the") is 3, because "the" has 3 characters.
-
Assume that linear probing is used to insert the keys. Determine which key causes overflow, and show the table at that point by adding the keys at the appropriate positions in the table that we have provided in section 7-1 of
ps8_partI. -
Now assume that quadratic probing is used. Determine which key causes overflow, and show the table at that point.
-
Finally, assume that double hashing is used, and that the second hash function
h2is based on the part of speech of the key, as follows:h2(k) = 1ifkis a noun or pronoun (e.g.,"we","my")h2(k) = 2ifkis a verb (e.g.,"do","go")h2(k) = 3ifkis an article (e.g.,"the","an")h2(k) = 4ifkis any other part of speech (the rest of the words above).
Determine which key causes overflow, and show the table at that point.
Now consider the fourth table provided for problem 7 in ps8_partI.
Assume that this table is using double hashing with the hash functions
described above. The table includes a
number of existing keys, and positions 2 and 7 are shaded to indicate
that they are removed positions – i.e., ones that used to hold an
item that has since been removed.
-
If we now insert an item whose key is
"see"(which is a verb), what is the probe sequence – i.e., the sequence of positions examined during probing – for that insertion? -
Show what the table will look like after
"see"is inserted.
Submitting your work for Part I
Note: There are separate instructions at the end of Part II that you should use when submitting your work for that part of the assignment.
Submit your ps8_partI.pdf file using these steps:
-
If you still need to create a PDF file, open your
ps8_partIfile on Google Drive, choose File->Download->PDF document, and save the PDF file on your machine. -
Login to Gradescope by clicking the link in the left-hand navigation bar, and click on the box for CS 112.
-
Click on the name of the assignment (
PS 9: Part I) in the list of assignments on Gradescope. You should see a pop-up window labeled Submit Assignment. (If you don’t see it, click the Submit or Resubmit button at the bottom of the page.) -
Choose the Submit PDF option, and then click the Select PDF button and find the PDF file that you created. Then click the Upload PDF button.
-
You should see a question outline along with thumbnails of the pages from your uploaded PDF. For each question in the outline:
- Click the title of the question.
- Click the page(s) on which your work for that question can be found.
As you do so, click on the magnifying glass icon for each page and doublecheck that the pages that you see contain the work that you want us to grade.
-
Once you have assigned pages to all of the questions in the question outline, click the Submit button in the lower-right corner of the window. You should see a box saying that your submission was successful.
Important
-
It is your responsibility to ensure that the correct version of every file is on Gradescope before the final deadline. We will not accept any file after the submission window for a given assignment has closed, so please check your submissions carefully using the steps outlined above.
-
If you are unable to access Gradescope and there is enough time to do so, wait an hour or two and then try again. If you are unable to submit and it is close to the deadline, email your homework before the deadline to
cs112-staff@cs.bu.edu
Part II
55 points total
Preparing for Part II
Begin by downloading the following zip file: ps8.zip
Unzip this archive, and you should find a folder named ps8, and
within it the files you will need for Part II.
Keep all of the files in the ps8 folder, and open that folder in VS
Code using the File->Open Folder or File->Open menu option.
Problem 8: Adding methods to the LinkedTree class
20 points; individual-only
We will complete the material needed for this problem during the week of April 11.
In the file LinkedTree.java, add code that completes the following
tasks:
-
Write a non-static
sumKeysTo(int key)method that takes takes an integer key as its only parameter and that uses uses iteration to determine and return the sum of the keys on the path from the root node to the node with the specified key, including the key itself. Your method should take advantage of the fact that the tree is a binary search tree, and it should avoid considering subtrees that couldn’t contain the specified key. It should return 0 if the specified key is not found in the tree.Note: There are two methods in the
LinkedTreeclass that can facilitate your testing of this method and the other methods that you’ll write:-
The
insertKeys()method takes an array of integer keys, and it processes the array from left to right, adding a node for each key to the tree using theinsert()method. (The data associated with each key is a string based on the key, although our tests will focus on just the keys.) -
The
levelOrderPrint()method performs a level-order traversal of the tree and prints the nodes as they are visited; each level is printed on a separate line. This method doesn’t show you the precise shape of the tree or the edges between nodes, but it gives you some sense of where the nodes are found.
For example, if we run the following test code:
LinkedTree tree = new LinkedTree(); System.out.println("for an empty tree: " + tree.sumKeysTo(13)); int[] keys = {37, 26, 42, 13, 35, 56, 30, 47, 70}; tree.insertKeys(keys); System.out.println("\nfor the tree from problem 6:"); System.out.println("sum to 13 = " + tree.sumKeysTo(13)); System.out.println("sum to 56 = " + tree.sumKeysTo(56)); System.out.println("sum to 37 = " + tree.sumKeysTo(37)); System.out.println("sum to 50 = " + tree.sumKeysTo(50));
we should see:
for an empty tree: 0 for the tree from problem 6: sum to 13 = 76 sum to 56 = 135 sum to 37 = 37 sum to 50 = 0
-
-
Write two methods that together allow a client to determine the number of leaf nodes in the tree:
-
a private static method called
numLeafNodesInTree()that takes a reference to aNodeobject as its only parameter; it should use recursion to find and return the number of leaf nodes in the binary search tree or subtree whose root node is specified by the parameter. Make sure that your method correctly handles empty trees/subtrees – i.e., cases in which the value of the parameterrootisnull. -
a public non-static method called
numLeafNodes()that takes no parameters and that returns the number of leaf nodes in the entire tree. This method should serve as a “wrapper” method fornumLeafNodesInTree(). It should make the initial call to that method – passing in the root of the tree as a whole – and it should return whatever value that method returns.
For example, if we run the following test code (which again includes building the tree from problem 6):
LinkedTree tree = new LinkedTree(); System.out.println(tree.numLeafNodes()); int[] keys = {37, 26, 42, 13, 35, 56, 30, 47, 70}; tree.insertKeys(keys); System.out.println(tree.numLeafNodes());
we should see:
0 4
-
-
Write a non-static method
deleteSmallest()that takes no parameters and that uses iteration to find and delete the node containing the smallest key in the tree; it should also return the value of the key whose node was deleted. If the tree is empty when the method is called, the method should return -1.Important: Your
deleteSmallest()method may not call any of the otherLinkedTreemethods (including thedelete()method), and it may not use any helper methods. Rather, this method must take all of the necessary steps on its own – including correctly handling any child that the smallest node may have.For example, if we run the following test code (which again involves building the tree from problem 6):
LinkedTree tree = new LinkedTree(); System.out.println("empty tree: " + tree.deleteSmallest()); System.out.println(); int[] keys = {37, 26, 42, 13, 35, 56, 30, 47, 70}; tree.insertKeys(keys); tree.levelOrderPrint(); System.out.println(); System.out.println("first deletion: " + tree.deleteSmallest()); tree.levelOrderPrint(); System.out.println(); System.out.println("second deletion: " + tree.deleteSmallest()); tree.levelOrderPrint();
we should see:
empty tree: -1 37 26 42 13 35 56 30 47 70 first deletion: 13 37 26 42 35 56 30 47 70 second deletion: 26 37 35 42 30 56 47 70
Note that first we delete 13, because it is the smallest key in the original tree. Next we delete 26, because it is the smallest remaining key. As a result of these deletions, 35 and 30 move up a level in the tree.
-
In the
main()method, add at least two unit tests for each of your new methods.-
Use the same unit-test format that we specified in Problem 8.
-
We have given you the beginnings of a test for part 1 that you should complete.
-
For part 2 (
numLeafNodesInTree()/numLeafNodes()), your unit tests only need to callnumLeafNodes(), since doing so will also callnumLeafNodesInTree().
-
Problem 9: Implementing a hash table using separate chaining
35 points; individual-only
In lecture, we discussed the following interface for a hash table ADT:
public interface HashTable { boolean insert(Object key, Object value); Queue<Object> search(Object key); Queue<Object> remove(Object key); }
We also examined one implementation of this interface that uses
open addressing (the OpenHashTable class that we’ve included in
the ps8 folder).
In this problem, you will complete another implementation of this
interface – one that uses separate chaining instead of open addressing.
Its class will be called ChainedHashTable.
We have given you a skeleton for this class in the ps8 folder.
It includes two private fields:
-
one called
numKeysfor the number of keys in the hash table -
one called
tablethat holds a reference to the array that you will use for the hash table. However, rather than having each element of the array store a single entry as we do in open addressing, each element of the array must serve as a bucket or chain of entries.
We have given you a private inner class called Node for the nodes in
each chain. Each element of the table array must hold a reference
to the first node in its linked list of nodes, and you will need to
create and manipulate these nodes within your hash table methods.
Each Node object has fields that allow it to store:
-
a single key
-
the collection of values associated with that key, using an instance of our
LLQueueclass -
a reference to the next node in the linked list (if any).
We have also given you:
-
a copy the
h1()method from ourOpenHashTableclass, which you must use as the hash function of your implementation (Note: Because separate chaining allows all entries whose keys are hashed to a given position in the table to stay in that position, you will not need to perform any probing. As a result, you won’t need the second hash functionh2()fromOpenHashTable.) -
a
toString()method that will allow you to see the current contents of the table. It returns a string of the form[table[0], table[1], ..., table[size - 1]]
where each position of the table is represented by either:
-
the key or keys in that position’s chain of entries, separated by semi-colons and surrounded by curly braces.
-
the word
nullif there are no keys in that position.
-
Your tasks
-
Review all of the provided code, and make sure that you understand it.
-
Add a constructor that takes the size of the hash table as its only parameter and initializes the hash table accordingly. It should throw an
IllegalArgumentExceptionif the size is not positive. -
Implement each method from the
HashTableinterface as efficiently as possible. Make sure that each of these methods has the same basic functionality as the corresponding method from theOpenHashTableclass discussed in lecture. In particular, they should throw exceptions for the same reasons that theOpenHashTablemethods do.As you add or remove items from the table, make sure that you update
numKeysaccordingly.Because a given chain can grow to an arbitrary length, the hash table will never overflow, and thus your
insertmethod can always returntrue. For example, if you run this test code:ChainedHashTable table = new ChainedHashTable(5); table.insert("howdy", 15); table.insert("goodbye", 10); System.out.println(table.insert("apple", 5)); System.out.println(table);
you should see:
true [{apple; howdy}, null, null, {goodbye}, null]Note that:
-
Position 0 has a chain with two keys, because both
"howdy"and"apple"are assigned a hash code of 0 byh1()when the table size is 5. -
Position 3 has a chain with one key, because
"goodbye"is assigned a hash code of 3 byh1()when the table size is 5.
-
-
Define an accessor method for the number of keys. Call this method
getNumKeys(). For example, this test code:ChainedHashTable table = new ChainedHashTable(5); table.insert("howdy", 15); table.insert("goodbye", 10); table.insert("apple", 5); System.out.println(table.getNumKeys()); table.insert("howdy", 25); // insert a duplicate System.out.println(table.getNumKeys());
should print:
3 3
because inserting a duplicate does not change the number of keys.
-
Although a hash table that uses separate chaining won’t overflow, it can become too full to offer decent performance. To allow clients to measure the degree of fullness, add a method called
load()that takes no parameters and that returns a value of typedoublethat represents the load factor of the table: the number of keys in the table divided by the size of the table.For example, this test code:
ChainedHashTable table = new ChainedHashTable(5); table.insert("howdy", 15); table.insert("goodbye", 10); table.insert("apple", 5); System.out.println(table.load()); table.insert("pear", 6); System.out.println(table.load());
should print:
0.6 0.8
-
To allow clients to obtain all of the keys in the hash table, add a method called
getAllKeys()that takes no parameters and that returns an array of typeObjectcontaining all of the keys in the hash table.For example, the following test code:
import java.util.*; ChainedHashTable table = new ChainedHashTable(5); table.insert("howdy", 15); table.insert("goodbye", 10); table.insert("apple", 5); table.insert("howdy", 25); // insert a duplicate Object[] keys = table.getAllKeys(); System.out.println(Arrays.toString(keys));
should print:
[apple, howdy, goodbye]
-
To deal with situations in which the table becomes too full, add a method called
resize()that takes an integer representing the new size, and that grows the table to have that new size. It should not return a value.As discussed in lecture, it is not possible to simply copy every element of the current table into a new, larger table. This is because a given key may belong in a different position in the larger table. As a result, you will need to rehash the current keys in the hash table to ensure that they end up in the correct position in the resized table.
For example, the following test code:
ChainedHashTable table = new ChainedHashTable(5); table.insert("howdy", 15); table.insert("goodbye", 10); table.insert("apple", 5); System.out.println(table); table.resize(7); System.out.println(table);
should print:
[{apple; howdy}, null, null, {goodbye}, null] [null, {apple}, null, null, null, {howdy}, {goodbye}]Note that in this case, resizing the table causes all three keys to end up in different positions!
Special cases:
-
The method should throw an
IllegalArgumentExceptionif the specified new size is less than the table’s current size. -
If the specified new size is the same as the table’s current size, the method should return without doing anything.
-
-
Add a
main()method that performs at least two unit tests for each of the methods in the class. Use the same unit-test format that we specified in Problem 8 of Problem Set 7.
Submitting your work for Part II
Note: There are separate instructions at the end of Part I that you should use when submitting your work for that part of the assignment.
You should submit only the following files:
LinkedTree.javaChainedHashTable.java
Make sure that you do not try to submit a .class file or a file
with a ~ character at the end of its name.
Here are the steps:
-
Login to Gradescope as needed by clicking the link in the left-hand navigation bar, and then click on the box for CS 112.
-
Click on the name of the assignment (
PS 9: Part II) in the list of assignments. You should see a pop-up window with a box labeled DRAG & DROP. (If you don’t see it, click the Submit or Resubmit button at the bottom of the page.) -
Add your files to the box labeled DRAG & DROP. You can either drag and drop the files from their folder into the box, or you can click on the box itself and browse for the files.
-
Click the Upload button.
-
You should see a box saying that your submission was successful. Click the
(x)button to close that box. -
The Autograder will perform some tests on your files. Once it is done, check the results to ensure that the tests were passed. If one or more of the tests did not pass, the name of that test will be in red, and there should be a message describing the failure. Based on those messages, make any necessary changes. Feel free to ask a staff member for help.
Note: You will not see a complete Autograder score when you submit. That is because additional tests for at least some of the problems will be run later, after the final deadline for the submission has passed. For such problems, it is important to realize that passing all of the initial tests does not necessarily mean that you will ultimately get full credit on the problem. You should always run your own tests to convince yourself that the logic of your solutions is correct.
-
If needed, use the Resubmit button at the bottom of the page to resubmit your work. Important: Every time that you make a submission, you should submit all of the files for that Gradescope assignment, even if some of them have not changed since your last submission.
-
Near the top of the page, click on the box labeled Code. Then click on the name of each file to view its contents. Check to make sure that the files contain the code that you want us to grade.
Important
-
It is your responsibility to ensure that the correct version of every file is on Gradescope before the final deadline. We will not accept any file after the submission window for a given assignment has closed, so please check your submissions carefully using the steps outlined above.
-
If you are unable to access Gradescope and there is enough time to do so, wait an hour or two and then try again. If you are unable to submit and it is close to the deadline, email your homework before the deadline to
cs112-staff@cs.bu.edu
Last updated on April 22, 2026.