CS791:A Critical Look at Network Protocols
Lecture date: 09/16/99
Prof. John Byers
Scribe: Alberto Medina
Last Time
Last class discussion analyzed the differences between congestion control (CC) and congestion avoidance (CA). We saw that congestion control is a reactive mechanism that reacts to congestion conditions once they are already happening. On the other hand, CA is a proactive mechanism which has the primary goal of maintaining the network at low congestion levels.
In the previous paper by Chiu and Jain we discussed two important curves: Load Vs. Throughput and Load Vs. Response Time. They defined for those curves two distinguished points: the cliff of the curve, which is the point in which further increase in the load to the network results in a radical fall in the throughput level and a radical increase of the response times, and the knee of the curve, which is the point in those curves where throughput was maximized and response time was minimized. In those terms, a CC mechanism tries to recover for congestion conditions in which the cliff of the curves is being approached, whereas a CA mechanism tries to keep the network operating at the knee of the curves. Keeping the network operating at the knee of the curves is equivalent to maximize the network power, that is, the ration of throughput to response time.
An example of a CC mechanism is the one used by the transport protocol TCP. In TCP, the loss of a packet at a router/gateway is interpreted an implicit signal of congestion. This in general a good indication of congestion given that the big majority of packet losses are due to congestion situations in which the queue at a router are overflowed and packets are necessarily dropped. At the moment that the source end host detects the loss of a packet, it decreases the amount of data it puts into the network (decreases its window size). We can see that relying on packet losses to "do something" means that the mechanism used "waits" until congestion is occurring to implement corrective measures.
An example of a CA mechanism is the one described in the first paper of today's discussion. The mechanism basically relies on the gateways to detect incipient congestion and notifies it to the sources so they can take preventive measures and avoid taking the network into a congested state.
It is important to note that CC and CA are not mutually exclusive mechanism, that is, they can coexist in the same network. Even when the CA mechanism tries to keep the network in "good shape", should it approach for any reason (e.g. misbehaving users) the cliff point, a CC mechanism must come into play to recover for such a congestion situation.
Another difference we discussed in last class was that between Flow Control (FC) mechanisms and Congestion Control/Avoidance mechanism. A FC mechanism addresses the problem of preventing the source overwhelming the receiver of a connection by sending more data than it can handle. By controlling the flow from the source to the receiver, the receiver is not forced to drop packets because of buffer overflows and the sender is not forced to make unnecessary retransmission as a consequence. On the other hand, a CC/CA attacks the global problem of maintaining a network, potentially shared by many connections at any given time, operating at levels of no congestion. As it described in the K.K. and Jain paper, FC mechanism address the "selfish" problem of a single connection whereas CC/CA mechanism address the "social" problem of a community of network users.
In the context of CC/CA we discussed several improvements made to TCP which had the goal of making TCP to avoid congestion more efficiently. The main idea of the improvements was to rely on the conservation of packets principle, which says that, a connection in equilibrium should not inject a new packet into the network until a previously injected packet leaves the network. Jacobson analyzed the possible reasons why a connection could violate such principle and proposed several "fixes" to TCP.
Finally, in last class we discussed the paper by Chiu and Jain "Analysis of the Increase and Decrease Algorithms for Congestion Avoidance in Computer Networks". The main idea we took home from that paper is that having sources additively increasing the load put into the network when the maximum throughput has not been achieved, and exponentially decreasing the load when the load put into the network is exceeding the optimal point, the network can converge quickly (depending on the constants selected) to the knee of the power function of the network and avoid wide oscillations.
Summary of Papers Read
Today we will discuss the following papers:
Summary of first paper
This paper proposes a CA mechanism, Binary Feedback (BF). The design of the mechanism was driven by the following goals: it must be distributed, it must adapt to the dynamic state of the network, it must converge to the knee of the network power function, is must be simple to implement, and it must have low overhead. The basic idea of the paper is relatively simple but the difficulties are found in the details. In general, evaluating complex ideas may be intractable. A general principle that should be followed is to make things as simple as possible for the sake of tractability and development of our ideas.
As we saw last class, one of the goals of a CA algorithm is to drive the operation of the network toward the knee of the delay curve, and that is one goal for the BF CA mechanism. One design challenge is to achieve all the set goals while using only a small field in the network layer field and as little bandwidth for explicit feedback information as possible.
What does the router do? A router that is congested sets a congestion indication bit in the network layer header of a data packet that is flowing in the forward direction. If a router is not congested, the congestion bit is simply ignored.
What does the receiver do? When the packet arrives at the destination, the congestion bit is copied into the transport layer header of the acknowledgement (ACK) packet and the ACK is transmitted back to the source.
What does the source do? Sources are required to adjust the traffic they place on the network, by adjusting their window size, based on their interpretation of the congestion indication from the network. Notice that this scheme requires cooperating users.
Top Level Issues
Selection of a performance metric.
The first point of discussion in the analysis is the choice of performance metric to be used as the optimization criteria. They define a function called Power at each router and use it to choose the operating point of the network so that we are at the knee of the delay curve. The power function has been widely used in the past. In order to use the power function at each router to determine the network operating point, they use a function called Efficiency, and the maximally efficient operating point for the resource is the knee of the delay curve. When the network is at any other point of operation other than the knee, a function is needed to measure the distance of that operation point from the maximally efficient one. They define the ration of the Resource Power to the Resource Power at the Knee as the Resource Efficiency. The desirable property of such a function is that it is 0 if the throughput is zero (and response time is infinite) and it is 100 at the maximally efficient point. So, the defined function allows to measure the resource efficiency. By inefficient use of a resource it is meant that the resource is either underutilized or overutilized.
Signaling Policy
Basically, the routers use a feedback signal to indicate congestion. Several signaling mechanisms have been studied in the literature but most of them require sending additional packets into the network. If signals must be transmitted to indicate the incipient congestion of the network, putting more packets into the network would make things worse.
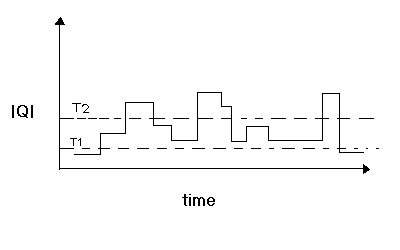
One question to ask is: how can we detect that the router is congested? One way would be to use the utilization levels. However, that is not such a good idea because the load of a router depends on the distribution of the service time. When there is a considerable variance on the packet size distribution, then the response time degrades even with relatively low utilization of the router. They use queue length as the indication of congestion at the router because it is less sensitive to the distribution of service times. The average queue length is measured at the router. Several algorithms can be used then to signal a congestion indication back to the source. Those algorithms can be categorizes as:
Suppose the following scenario:
in which we have a router in isolation associated with a queue of packets to forward. Two thresholds, T1 and T2 are defined for the size of the queue. The simple thresholding algorithm is to generate the feedback signal when the queue size is above the threshold, say T2. On the other hand, the hysterisis algorithm indicates congestion when the queue size is increasing and crosses a threshold value, say T2. The feedback signal is then kept the same until the queue size decreases and reaches a smaller threshold, say T1. The idea of the hysterisis algorithm is to reduce the amount of feedback signals generated. For example, if a single threshold is used, the following scenario may occur:
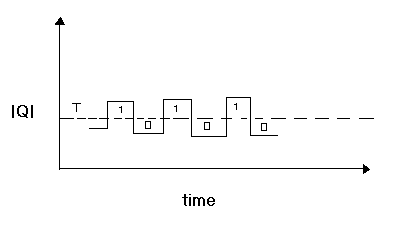
Where the congestion signal goes back and forth from 0 to 1 and back to 0. This causes to many congestion signals to be send when the queue size oscillates very close to the threshold value defined. having two thresholds as defined above avoids this problem. Now, hysterisis is proposed to reduce the amount of communication involved in notifying congestion. Because the binary feedback scheme does not involve additional packets, they use the simple thresholding policy in which the router sets the congestion bit on packets that arrive when the average queue length is greater than or equal to 1.
Computing the Average Queue length
In order to avoid sudden reactions to transient congestion levels, instantaneous queue lengths are not used at the router. Instead an average queue length is computed over an appropriate time interval. The idea is to have a low-pass filter function to pass only those queue states that are expected to last long enough to be meaningful. The way this is achieved in the paper in by setting the congestion bits for packets that arrive when the average queue length is greater than or equal to one.
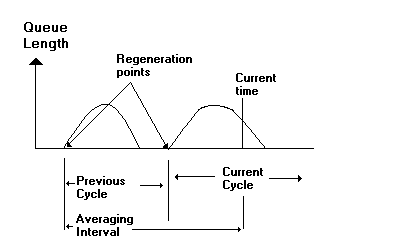
The question to ask now is which is the right time interval to compute the average queue length? They found that using a simple scheme such as computing the average over a fixed time interval was not good when the interval is not close the round-trip delay from the users. Next they tried a weighted exponential running average of the queue length. That scheme also showed the problem of having inconsistent signals transmitted to the users. They used then an adaptive algorithm which basically determines the busy/idle period at the router. The regeneration cycle at a router is a busy + idle sequence. The average queue length is computed as the area under the curve divided by the total time of the regeneration point. See the next figure:
What Happens at The Source?
Once the router has measured the average queue length and it has decided marking a packet (or not marking it), the source must take the appropriate actions indicated by the router. Following are the design decisions made in the paper.
Decision Frequency
The approach adopted was to introduce a waiting period after every window size update before the next update is done. The consequence of adopting this approach is that the oscillations in the window size are reduced.
Use of Received Information
The source examines only the congestion bits for a number of packets corresponding to the size of the current window size. The idea is to keep the policy simple and avoid maintaining additional state.
Signal Filtering
The algorithm adopted in the paper consists of using a single cutoff factor for the filtering of the signal at the decision maker. The main idea is again simplicity. The cutoff factor selected is 50%. If 50% of the received acknowledgements have the congestion bit set, then actions must be taken.
Increase/Decrease Algorithm for the Window Size
For reasons explained in the Chiu-Jain paper last week, the Increase/Decrease algorithm selected is AIMD (Additive Increase/Multiplicative Decrease).
Summary of Second Paper
The paper by Karn and Patridge addresses the problem of accurately setting retransmission timers. The goal is to avoid spurious retransmissions and to avoid bandwidth waste in the network.
The main problem they attack is the ambiguity that exist when packets are retransmitted: when the acknowledgement for a packet that was retransmitted arrives at the source, there is no precise way of telling whether the ack was for the original packet or for the retransmitted packet. One could guess that the ack is for the original retransmission or, alternatively, that it was for the last retransmission. If take the first alternative and the ack was actually for the retransmission, we would be giving an estimated RTT too large. This case is not desirable because we would reduce the amount of data injected into the network by increasing the value of the estimated RTT. However, it is not too dangerous. On the other hand, if we take the second option and the ack was for the original, then we would be underestimating the RTT measurement. This scenario is dangerous because the actual large RTT is very likely indicating existing congestion in the network and, by underestimating the RTT, the source would contribute more to increase the congestion level.
he solution proposed and implemented by Karn is simple: Ignore measurements for retransmitted packets. This has to be done carefully because just ignoring them could stale the estimated RTT and the source would not be able to react to the building congestion in the network. Thus, the value of the retransmission timeout (RTO) is doubled until more accurate measurements are obtained.
The idea of this paper is simple, elegant and easy to implement.