These notes collect together a number of important recursive algorithms operating on linked lists.
The basic data declaration for Nodes is the same as in the textbook and lecture.
All the code below assumes the following declaration:
public class Node {
public int item;
public Node next;
Node() { // this would be the default, put here for reference
item = 0;
next = null;
}
Node(int n) {
item = n;
next = null;
}
Node(int n, Node p) {
item = n;
next = p;
}
};
We will assume that there is a variable which points to the head of the list:
Node head;
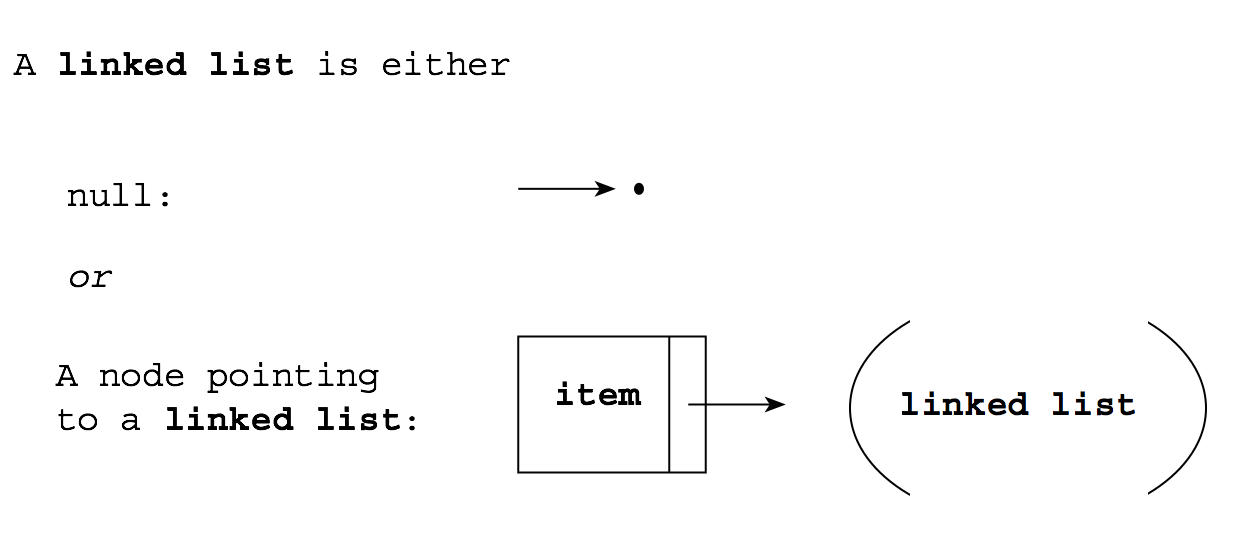
The power of recursive algorithms becomes most obvious when they are applied to data structures which are themselves recursive. In the case of linked lists, we will see that recursive algorithms are almost always shorter and simpler, once you are comfortable with the notion of recursion. Here is a recursive definition of a linked list:
We will see that almost all recursive algorithms on linked lists follow this definition:
recAlgorithm(Node p .... ) {
if (p == null) {
// base case:
do something simple
}
else {
// recursive case:
do something at the head of the list, then
call the method on the rest of the list:
recAlgorithm(p.next .....)
}
The recursive algorithms depend on a series of method calls to chain along the list, rather than an explicit for or while loop. The recursive versions of most linked-list algorithms are quite concise and elegant, compared with their iterative counterparts, as most of the special cases are eliminated.
A simple recursive function.
int length( Node p ) {
if (p == null)
return 0;
else
return 1 + length( p.next );
}
// Example call:
int len = length(head);
Again, a simple function which recurses down the list, and stops at the end (not found) or when it finds the key:
boolean member( int k, Node p ) {
if (p == null)
return false;
else if( k == p.item )
return true;
else
return member( k, p.next );
}
// Example call:
if( member( 5, head) ) .....
This is a simple algorithm, and good place to start in showing the simplicity and complexity of of recursion. Recursion allows us flexibility in printing out a list forwards or in reverse (by exchanging the order of the recursive call)---try to write a simple printReverseList using iteration!
void printList( Node p ) {
if (p != null) {
System.out.println(p.item);
printList( p.next );
}
}
void printReverseList( Node p ) {
if (p != null) {
printReverseList( p.next ); // just exchange the order of the two lines in the previous!
System.out.println(p.item);
}
}
// Example of use:
printList( head );
What do the following print out?
head -> 4 -> 2 -> 7 -> null
void printList1( Node p ) {
if (p != null) {
System.out.println(p.item);
System.out.println(p.item);
printList1( p.next );
}
}
void printList2( Node p ) {
if (p != null) {
System.out.println(p.item);
printList2( p.next );
System.out.println(p.item);
}
}
void printList3( Node p ) {
if (p != null) {
System.out.println(p.item);
printList3( p.next );
printList3( p.next );
}
}
void printList4( Node p ) {
if (p != null) {
printList4( p.next );
System.out.println(p.item);
printList4( p.next );
}
}
void printList5( Node p ) {
if (p != null) {
printList5( p.next );
printList5( p.next );
System.out.println(p.item);
}
}
Node construct( Node p ) {
if( p == null )
return null;
else {
p.next = construct( p.next );
return p;
}
}
// Example of use:
head = construct( head );
Pretty silly, right? But if we use this as a basis for altering the list recursively, then it becomes a very useful paradigm. All you have to do is figure out when to interrupt the silliness and do something useful. Here is a simple example, still kind of silly:
Node addOne( Node p ) {
if( p == null )
return null;
else {
p.next = addOne( p.next );
++p.item;
return p;
}
}
// Example of use:
head = AddOne( head );
This recursively traverses the list and adds one to every item in the list. Following are some definitely non-silly algorithms using the approach to traversing the list.
This one is extremely simple, useful and not at all silly. Instead of reconstructing the same list, reconstruct another list, thereby building a copy (compare with the complicated iterative version!):
Node copy( Node p ) {
if( p == null )
return null;
else
return new Node(p.item, copy( p.next ));
}
// Example of use
newList = copy( head );
I'll repeat again that when using this "reconstruct the list" paradigm, the special case of empty lists and insertion at the beginning do not occur, and the algorithm is much simpler; this next algorithm shows the advantage:
Node insertInOrder( int k, Node p ) {
if (p == null) {
return new Node( k, null );
} else if (p.item >= k ) {
return new Node( k, p );
} else {
p.next = insertInOrder( k, p.next );
return p;
}
}
// Example of use:
head = insertInOrder( 7, head );
This algorithm deletes the first occurrence of an item from a list. A simple change enables this algorithm to delete all occurrences of the item, by continuing to chain down the list after the item has been found. We assume that the list is unordered; you can easily change this to stop after finding a item beyond the search item by changing the first if condition.
Node delete( int k, Node p ) {
if (p == null) // if the list is ordered use: ( p == null || p.item > k )
return p;
else if (p.item == k)
return p.next; // if you want to delete all instances, use: return deleteItem( k, p.next );
else {
p.next = delete(k, p.next);
return p;
}
}
public static Node deleteLast( Node p ) {
if( p == null || p.next == null )
return null;
else {
p.next = deleteLast( p.next );
return p;
}
}
Appending two lists is a simple way of creating a single list from two. This function adds the second list to the end of the first list:
Node append( Node p, Node q ) {
if ( p == null)
return q;
else {
p.next = append( p.next, q );
return p;
}
}
Example of use
head = append(head, anotherList);
Here is a method which alternately takes a node for each of two lists, effectively shuffling or zipping up the two lists into one:
Node zip(Node p, Node q) {
if (p == null)
return q;
else if (q == null)
return p;
else {
Node pNext = p.next;
Node qNext = q.next;
p.next = q;
q.next = zip(pNext,qNext);
return p;
}
}
// Here is an interesting alternative, which flips back and forth between the two lists in the recursive calls:
Node zip(Node p, Node q) {
if (p == null)
return q;
else {
p.next = zip(q, p.next); // note how q is now the first argument
return p;
}
}
Here is another more complex function to combine two lists; this one merges nodes from two sorted lists, preserving their order:
Node merge( Node p, Node q ) {
if ( p == null)
return q;
else if ( q == null)
return p;
else if (p.item < q.item) {
p.next = merge( p.next, q );
return p;
}
else {
q.next = merge( p, q.next );
return q;
}
}
Example of call:
head = merge( head, anotherlist );
A typical algorithm on a linked list is to do some kind of running sum or other calculation, either as you go down the linked list (returning the result at the end), or by doing the calculation on the way back up. The second algorithm for a reversed list just given was of the first type. We will illustrate using two approaches to summing all the numbers in a linked list.
// examples to show how to keep an accumulator (e.g., sum) while recursing through a list
// Example 1: calculate running sum as recurse BACK up list, e.g.,
// -> 2 -> 3 -> 65 -> 4 -> .
// (2 + (3 + (65 + (4 + 0))))
public static int sumList1(Node p) {
if(p == null)
return 0;
else
return (p.item + sumList1(p.next));
}
public static int sumList2(Node p) {
return sumListHelper2(p,0);
}
// Example 2: Keep running sum on way DOWN the list, using tail-recursion
// -> 2 -> 3 -> 65 -> 4 -> .
// ((((0 + 2) + 3) + 65) + 4)
private static int sumListHelper2(Node p, int sum) {
if(p == null)
return sum;
else
return sumListHelper2(p.next, (sum + p.item));
}
In the notes on iterative LL algorithms we considered a rather complicated way to reverse two lists using three pointers which trail each other down the list. Now we consider two different versions of a recursive algorithm to reverse a LL. The first one uses a slight modification of the append method, which adds one list to the end of the other, but the list being added is only a single node!
// Add node t to the end of list
private static Node addToEnd( Node t, Node list ) {
if( list == null ) {
t.next = null; // just in case, make sure new end of list is null
return t;
}
else {
list.next = addToEnd(t,list.next);
return list;
}
}
private static Node reverseList( Node list ) {
if( list == null )
return null;
else {
Node temp = reverseList( list.next );
return addToEnd( list, temp ); // list is used here as a pointer to the single node at head of list
}
}
It is instructive to compare this with the version of reverse2 that we presented in the iterative notes (they are the same, if you translate the loop into recursion).
The problem with this last solution is that is is Theta(n2), because is has to travel all the way to the end of lists of length 1, 2, ...., N. A better way to reverse a list recursively is to simulate the way you could reverse a list by pushing all the elements onto a stack, then popping them off. Here, we use two parameters which act as stacks; we pop from the first parameter and push onto the second:
public static Node reverse(Node p) {
return reverseHelper(p, null);
}
public static Node reverseHelper(Node p, Node q) { // p is a stack that we pop from, and q a stack we push onto
if(p == null)
return q; // when p is null, we are done and return q.
else {
Node rest = p.next; // pop p off and save rest of list
p.next = q; // push the node p onto the list q
return reverseHelper(rest, p); // continue
}
}
Some other recursive algorithms(in increasing order of difficulty) you might want to try writing along the lines of those above are: