Abstract
Accurate tracking of the 3D pose of animals from video recordings is critical for many behavioral
studies, yet there is a dearth of publicly available datasets that the computer vision community could
use for model development. We here introduce the
Rodent3D dataset that records animals exploring
their environment and/or interacting with each other with multiple cameras and modalities (RGB,
depth, thermal infrared). Rodent3D consists of 200 minutes of multimodal video recordings from
up to three thermal and three RGB-D synchronized cameras (approximately 4 million frames). For
the task of optimizing estimates of pose sequences provided by existing pose estimation methods,
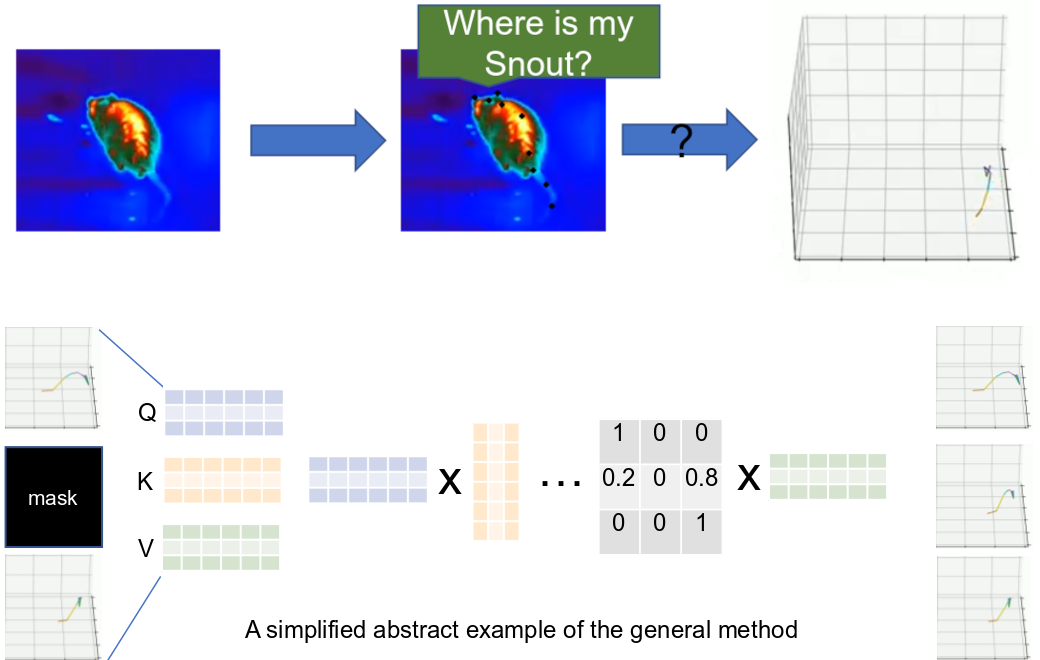
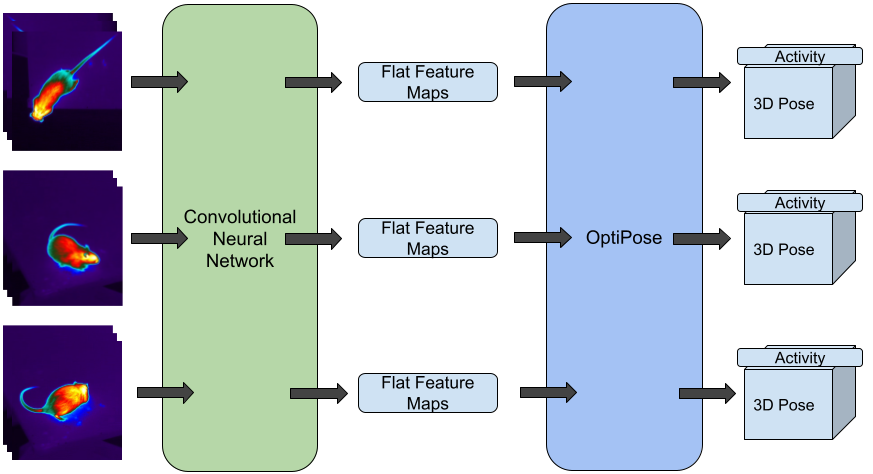
we provide a baseline model called OptiPose. While deep-learned attention mechanisms have been
used for pose estimation in the past, with OptiPose, we propose a different way by representing 3D
poses as tokens for which deep-learned context models pay attention to both spatial and temporal
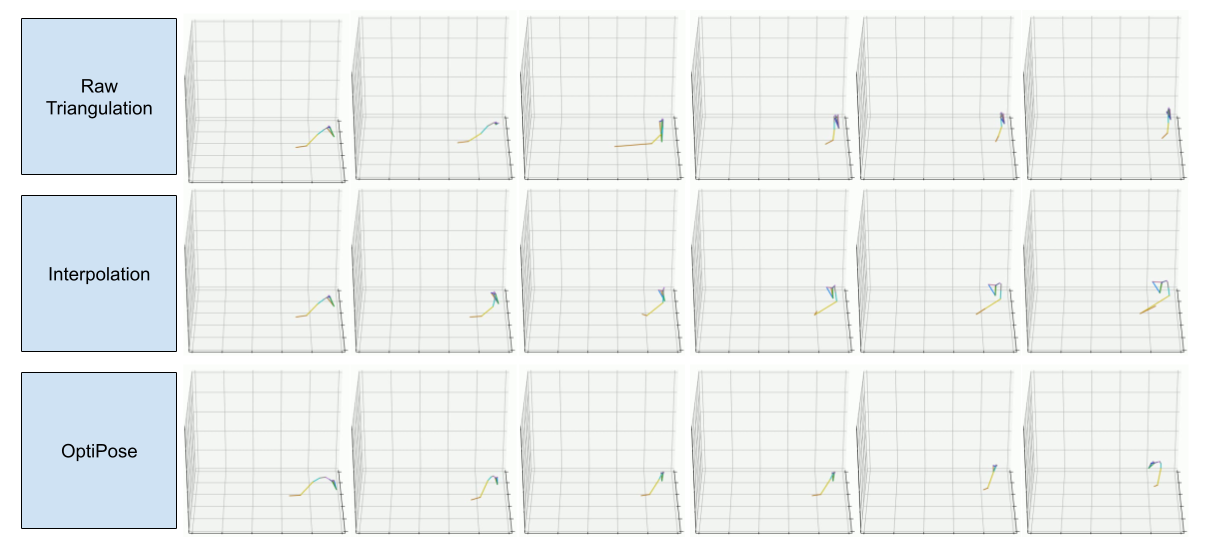
keypoint patterns. Our experiments show how OptiPose is highly robust to noise and occlusion and
can be used to optimize pose sequences provided by state-of-the-art models for animal pose estimation.
OptiPose 
MuSeq Pose Kit
alpha