What Does it Take to Get a Web Page?
Goal
As we repeatedly mentioned in class, an abstraction frees us from having to worry about (or be experts in) the nitty-gritty details underlying a complex system, while still allowing us to do useful things with that system -- whether this system is natural (e.g., population growth process), social (e.g., public opinions and trends), or engineered (e.g., the Internet and Web).
-
For natural and social systems, what we can "do" with them (through abstraction) is answer questions to better understand them or make statements about them.
-
For engineered systems, what we can "do" with them is build more functionalities on top of them -- thus making them more useful (and more complex).
In this lab module, we will take a functionality that is quite useful (and which we take for granted all the time) -- namely getting information from the web -- and look "under the hood" to see how this functionality is built on top of the following abstractions, each of which is simple on its own, but when combined "or layered" with the others, they deliver fairly powerful capabilities:
-
DNS: The "Domain Name Service" abstraction of an Internet-wide directory service that allows us to map user-friendly names to IP addresses.
-
TCP: The "Transmission Control Protocol" abstraction of a wire connecting two programs speaking the Hyper-Text Transfer Protocol (HTTP) language/vocabulary.
-
IP: The Internet Protocol abstraction of packet delivery allowing a single packet to make its way (through repeated routing and forwarding between routers) from a sender to a receiver.
Lab Worksheet
Click here for a worksheet that you should complete and hand in to the Teaching Assistant before you leave the laboratory.
Lab Overview
In this lab module, we will go through a drill that takes us through all the steps needed to fetch web content over the Internet. We will do so manually -- i.e., we will pretend to be the computer running a web browser, and we will go through all the steps that the computer would have had to go through to fetch that web content.
In particular, assume that you are asked to fetch the content available at the following URL:
Let's understand what the URL above tells us.
-
First, the URL tells us that the content of interest can be retrieved from the Internet using "HTTP" -- the Hyper-Text Transfer Protocol. HTTP is a "language" that allows web servers (computers that host the content) and web clients (computers that want to retrieve that content) to talk to one another. As you recall from lecture, to communicate with a web server running on a specific machine, we would do so using port #80 on that machine.
-
Second, the URL tells us that the machine we are interested in, i.e., the one running the web server, has the name "cs.stanford.edu". Recall that to communicate with a machine, we must do so using the machine's IP address. But since IP addresses are hard to remember, computer "names" are used instead. Such names can be mapped to IP addresses using a directory service called DNS.
-
Third, the URL tells us that the specific piece of content of interest on the web server is the file "/robots.txt", i.e., a file named "robots.txt" in the main directory of the web server machine's file system.
With the information above, we have all that is needed to (hopefully) get the content.
Task 1: Looking up the IP address of the remote host
First, in order to contact the remote host (a.k.a., the machine running the web server), we must come up with the IP address of that host. To do so we rely on the DNS service to tell us the IP address corresponding to the computer named "cs.stanford.edu".
There are many web tools that allow us to do this name lookup. Let's try the one at http://www.kloth.net/services/nslookup.php. By typing the name "cs.stanford.edu" in the domain field and clicking the "Look it up" button, we get the following
|
DNS server
handling your query: localhost |
Let's understand what the above result means.
The first two lines give us information about who is doing the lookup for us. In particular, it says that our request was handled by the local (default) DNS server which has a special IP address "127.0.0.1" and as one would expect from our discussion in lecture is associated with port #53.
The last two lines give us the answer: the IP address of cs.stanford.edu is 171.64.64.64. Notice that on the preceding line, this answer was qualified as being "Non-authoritative" because the DNS server we used was the "local" one as opposed to the one at "stanford.edu" which is responsible for "cs.stanford.edu".
Recall that as we discussed in class, the DNS system is a hierarchy (a tree) of directory services. At the root of that hierarchy, there is a directory able to point us to the directory service for ".edu" domains, from that we can get the directory service for "stanford.edu", which when asked will be able to tell us what is the IP address of "cs.stanford.edu".
All these directory services can be contacted by talking to a program associated with port #53 of the machine running the directory service.
Task 2: Getting an authoritative answer for host name lookup
If we want to find an "authoritative answer" we would have to contact the DNS service for "stanford.edu". To find where that service is, we use the same web tool as above, but instead of typing "cs.stanford.edu" in the "Domain" field, we would type "stanford.edu" and we would specify "NS (name server)" in the "Query" field since we are interested in finding the "Name Server" of "stanford.edu". Doing so we get:
|
DNS server handling your query: localhost |
So, there are four name servers that we can contact to get an authoritative answer. Now, if we go back and use the web tool again, but now using one of the above name servers (e.g., "Argus.stanford.edu" instead of the "local" (default) one we used before, we get the following:
|
DNS server handling your query: Argus.stanford.edu |
Now notice that we do not get the warning that the answer was "Non-authoritative" and (perhaps expectedly) we got the same IP address for "cs.stanford.edu".
Task 3: Contacting the web server program on the remote host
Now that we know the IP address of "cs.stanford.edu", we are ready to contact the web server associated with port #80 to request the file "/robots.txt". To do so, we will follow the script we used in class.
First we need to be able to run a telnet session. Telnet can be run from any machine by getting to a command prompt and then starting such a session. To do so, follow the following steps to get to a command prompt:
-
From the start menu, select the submenu "Unix Tools", and then select the program "putty"
-
Type "csa2.bu.edu" in the Host Name field and click Open
-
A command prompt will show up with the text "Login as:"
-
Type your username and then your password.
-
The command prompt will change to "[username@csa2 ~]$"
We are now ready to start a telnet session from our computer. A telnet sessions allows us to contact and interact with a program running on a remote computer on a specific port number. Basically, it establishes a two way communication (remember the "Lover's Phone" analogy) through which we can "talk" to the program on the other end. We do so by typing: "telnet [ip-address] [port-number]" at the command prompt. The IP address we want is 171.64.64.64 and the port number is 80. So, we would type
telnet 171.64.64.64 80
Doing the above will result in the web server program (attached to port #80 on that machine) to respond indicating that it is ready to talk with us. But, how do we "talk" with it?
Recall that the vocabulary (and specific exchanges) used to talk between programs on different computers is called a protocol. And, as we realized from the outset, to get the content we want, the protocol to be used is HTTP. To get a file using the HTTP protocol we use the command "GET" followed by the filename we want. So, we type:
GET /robots.txt
Doing so will result in the web server program fetching that file and sending it, resulting in the following to appear on our screen:
|
User-agent: * |
Here is a screenshot with the entire telnet session interactions.
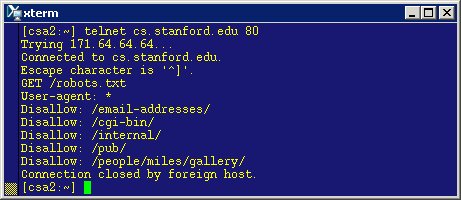
We did it! And to make sure, we can compare what we got with what we would get had we done all this using a web server, we can check http://cs.stanford.edu/robots.txt.
One last note about HTTP. We only used one "verb" from its vocabulary (the GET command). Of course, there is a lot more to that protocol than this simple command. For example, there are commands not only to get content but to "put" content (i.e., store it on the web server). And, there are commands to get an arbitrary part of a file, or to get different types of files, etc. But, the main concept is the same -- there are two programs one local (the browser) and one remote (the web server) who can speak a mutually understandable language and hence exchange information. Also, notice that this exchange is totally oblivious to how the information is sent over the Internet. Indeed, in all of the above, we had the illusion that whatever we type goes over a "wire" to the other side. We are given an abstraction of the Internet (thanks to TCP). The reality (as we know) is far more complicated.
The beauty of an abstraction is that it frees us from having to worry about (or be experts in) the nitty-gritty "details" under the hood. It gives us a solid base upon which we can build even more powerful abstractions -- this is what we have been doing in our examination of how the Internet works.
(Optional) Task 4: What exactly is "robots.txt"?
By the way, and just in case you wonder what is the meaning of the information in the "robots.txt", here is the scoop!
As you know many services such as Google and Bing "crawl" the web looking for content. In the case of Google and Bing, this "crawling" is for the purpose of indexing the content for searching purposes. This crawling is not done by humans, but rather by computer programs, which we can think of as "robots".
So, when we put up a web site on the Internet (such as www.stanford.edu), we should expect that the site will sooner or later be visited by robots who will go on and read the various pages on the site. This is a good thing, if we want such pages to be indexed and found (through search). But, not all files on a web site have information that would be useful for people to search for. For example some files may be "programs" that would be incomprehensible for humans, and yet other files may be ones that we do not want search engines to see.
To tell robots which files on a web site are OK to crawl and which ones are not OK to crawl, a convention developed -- namely that web sites will have a file called "robots.txt" in their main directory that includes instructions regarding what parts of the web site are fair game for crawlers and what parts should not be crawled.
Now, we can make sense of the information we retrieved above! It identifies five subdirectories of the web site that should be out of reach (disallowed) for robots.
Of course you may ask: So what? Couldn't a crawler simply ignore the instructions in the robots.txt and still crawl disallowed contents? The answer is yes, crawlers can do that. But, such accesses are recorded and eventually the web site administrators will find out and may "black list" the crawler from ever accessing their site -- which is certainly enough of a disincentive for crawlers such as Google's and Bing's...
Now that you know that this convention exists, you should realize that all the concerns about "search engines and content aggregators taking content for free" and then using it to their advantage (e.g., http://news.google.com) are completely unfounded: if you don't want crawlers of search engines to take your content, just tell them not to by putting that information into "robots.txt".
Task 5: What does it take for a packet to go from East Coast to West Coast?
Well, if we really want to know what it takes to get a web page, we cannot just stop at the "TCP" abstraction of a wire (which we were able to see in action through the use of "telnet"). So, let's go one layer down and find out what is happening under the TCP hood.
When information is sent over TCP, we think of it as a sequence of characters (and since everything is bits, then it is just a sequence of bits). The amount of information we can send over the TCP "wire" could be as large as we want -- e.g., a multi-hour movie consisting of Gigabytes of information. To send this stream of bits, TCP uses the IP protocol. It does so by splitting the information into a sequence of IP packets, each of which is individually addressed using the IP address and the port number of the sender and of the receiver, and each of which is individually routed through the Internet by being stored and forwarded from router to router along a path from the sender to the receiver (figuring out how to come up with this route is a different subject that we also considered).
To see this process in action, we will follow the path that a packet takes from the computer that runs the browser to the computer that runs the server.
To see this, we will use a tool -- called traceroute -- that we saw earlier in the class. Traceroute allows us to identify the sequence of routers along a route, as well as the time delays from one router to the next along that route. One can run traceroute from the command prompt of a Windows or a Unix machine (as demonstrated in class). The command is quite simple. For unix it is "traceroute [remote IP address]" and for Windows it is "tracert [remote IP address]".
So, to trace the routes that packets take from a local computer to cs.stanford.edu, at the command prompt we would type:
traceroute cs.stanford.edu
Here is what comes out when trying this from the same machine we used before using "Putty" (csa2.bu.edu):
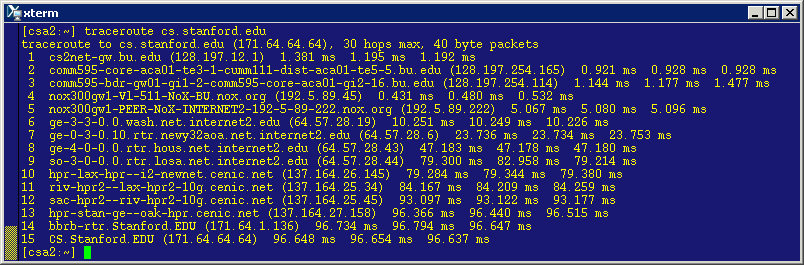
The route suggests that each packet sent from csa2.bu.edu to cs.stanford.edu went through 15 hops, going through 14 different routers! That's a lot of action under the hood!
Looking at the trace, we can make some interesting observations.
Looking at the names of the routers we can recognize a couple of acronyms for on-campus addresses (e.g., 111 Cummington and 595 CommAve -- csa2.bu.edu is housed in the CS Department at 111 Cummington). We can also recognize a couple of city names on the west coast (e.g., LA and Oakland).
Notice that for each router along the way, traceroute gives an estimate of the delay up to that router and back (called the round-trip time or RTT). Notice that such delays are variable (e.g., depending on how congested the network is up to that router) and may change. This is why traceroute makes multiple measurements for each hop and returns the results observed for all experiments. The default number of experiments is 3. So, this is why we get three numbers for each router. Indeed, we can ask for more measurements. For example, if we want to override the default and say request five (instead of three) measurements per hop, we can do so using the following command:
traceroute -q 5 cs.stanford.edu
To find out the RTT between two routers along the path, all we have to do is subtract the RTT for the first from the RTT for the second router. For example, to find the RTT between (say) the 5th and 6th routers (i.e., the RTT of the 6th hop), we would subtract the RTT for the 5th router (around 5 milliseconds) from the RTT for the 6th router (around 10.2 milliseconds), which would give us a RTT of around 5.2 milliseconds. A millisecond (abbreviated as msec or ms) is one thousands of one second.
By looking at the delays in the above results, we can conclude that the RTT for a packet across the US takes around 100ms, which means that the one-way delay would be 50ms. So, in one second, a packet can make 10 round trips across the US. Also, we note that the large hops occur in the middle of the route; this is when the packet is on the Internet "backbone" (think of this as the "highway" of the Internet). Indeed, three of the hops (going from the 6th to the 7th to the 8th router ) take almost 60% of the time, with one of those hops taking an RTT of 30msec (going from 8th to 9th router). Does this time delay suggest distances traveled? That's a question we will try to answer later in the course.
Just for the fun of it, assuming that the east-west distance across the US is ~ 3,000, the physical speed of the packet is 3,000/0.05 = 60,000 miles per second, which is about a third of the speed of light. Notice that in fact the distance traveled by a packet may be much longer than the physical distance between east coast and west coast since the routers are not lined up in a straight line!
Another way to look at this is to start from the speed which which a packet can move through a coaxial cable -- which is about 66% of the speed of light, i.e., 120,000 mph. Going with that speed for 50 msec means that the packet must have traveled 6,000 miles (i.e., twice the direct distance).
Incidentally, US universities are connected to one another using a privileged backbone called Internet2 (details at http://www.internet2.org) which allows for significant communication capacities to allow for scientists to collaborate by exchanging huge data sets unhindered by slower/busier connections (which is the case with commercial carriers). Four of the routers in the above trace are on Internet2.
(Optional) Task 6: Looking at the Reverse Path
Running traceroute from BU will allow us to discover and characterize the path from BU to any other IP address, but it does not allow us to do discover paths that do not start at BU. To allow Internet researchers and operators to "debug" the Internet, a number of institutions (not just universities, but research labs, commercial entities, etc.) offer a service on the web that allows anybody to trace a route from these institutions to any other IP address. A list of such servers is kept at http://www.traceroute.org. Checking that web site, we will find out that Stanford University is a participant -- which means we can trace the route from Stanford to BU. The web site (at Stanford) which makes this tool available is http://www.slac.stanford.edu/cgi-bin/nph-traceroute.pl?choice=yes, which by default will traceroute from that server at Stanford to the local machine, but will also allow for doing a traceroute to any IP address we enter in the input field.
Here are the results of doing a traceroute from that Stanford web site to "csa2.bu.edu" (Stanford removes the first two hops inside their network for security purposes).
|
Executing exec(traceroute, -m 30 -q 1 -w 3 -f 3, 128.197.12.4,
140) |
Unfortunately, notice that "www.slac.stanford.edu" is not the same host as "cs.stanford.edu", so we cannot really glean much by comparing this trace to the one we did before. Instead we should compare this trace to a trace from "csa2.bu.edu" to "www.slac.stanford.edu" (which we can do as before). Here are the results of doing so.
|
[csa2:~] traceroute www.slac.stanford.edu |
What can we glean by comparing these two traces (one going west to east and the second going east to west). First, we notice that the number of hops between "csa2.bu.edu" and "www.slac.stanford.edu" is (perhaps unsurprisingly) the same. We also note that the one-way delay between "csa2.bu.edu" and "www.slac.stanford.edu" is about the same, but about 25% shorter than the one we had before between csa2.bu.edu and cs.stanford.edu. We also notice that the path does not go through Internet2, which explains the discrepancy. As a matter of fact, it goes through another backbone called the Energy Science Network (details at www.es.net). SLAC is a particle physics research lab at Menlo Park (see www.slac.stanford.edu) which explains the association with the Energy Science Network as opposed to Internet2.
Additional Ideas and Further Experimentation...
-
Try out the cool visualization at http://visualroute.visualware.com/
-
Use traceroute as a sampling tool to check the routes between different hosts advertised on www.traceroute.org -- for example to characterize the number of hops on the Internet, or the proportion of paths on the Internet shorter than (or longer than) some value. Use what you learned in statistics to build confidence intervals around these proportions.
-
In class, we discussed the concept of "hot potato routing" which results in a route in one direction to be different from the route in the opposite direction (between the same two hosts). Can you use traceroute to show that this is the case?
Azer Bestavros (11/13/2010)