Carlos R. Cunha Azer Bestavros Mark E.\
Crovella
Computer Science Department
Boston University
111 Cummington St,
Boston, MA 02215
{carro,best,crovella}@cs.bu.edu
BU-CS-95-010
Tue Jul 18 10:53:00 EDT 1995
The recent proliferation of new information services on the Internet along with the enormous potential for commercial use of the Internet has increased the need for efficient protocols to reduce Internet traffic. The introduction of the World Wide Web (WWW) and the explosion in network traffic attributed to it [9] means that an accurate picture of WWW traffic is extremely important for evaluating various bandwidth-reduction techniques --- such as information caching, dissemination, and discovery protocols. Records of traffic to any particular server are readily available, as each server typically logs the requests it serves. However, server logs do not reflect the access patterns of individual users. Thus, they have been used to evaluate system-level performance metrics such as network bandwidth demand and server load, but they cannot be easily used to study user-level performance metrics such as service time. Client-based traces, in contrast, have limited value in the evaluation of system-level performance metrics or the study of global properties, but are central in evaluating user-level performance metrics and access patterns.
Unfortunately, client-based traces of WWW traffic are not widely available. To address this need, and to support our own research into client-level techniques for WWW traffic reduction, we captured a large number of client traces, recording the document reference patterns and times resulting from real users accessing the WWW.
In this paper we describe our method of trace collection, which is based on instrumenting the WWW browser NCSA Mosaic. In addition, we present a descriptive statistical summary of the traces we collected, which identifies a number of trends and reference patterns in WWW use. In particular, we show that many characteristics of WWW use can be modelled using power-law distributions, including the distribution of document sizes, the popularity of documents as a function of size, the distribution of user requests for documents, and the number of references to documents as a function of their overall rank in popularity (Zipf's law). In addition, we show how summary statistics derived from our traces can be used to guide system designers interested in caching WWW documents.
To our knowledge, these are the first such traces generally available to
the research community. The traces are available to the
public via anonymous FTP.![]()
The first step in understanding patterns of WWW use is the collection of trace data. Previous file-oriented studies have focused on reference patterns established based on logs of proxies [8,14], or servers [13]. The authors in [3] captured client traces, but they concentrated on events at the user interface level in order to study browser and page design. In contrast, our goal in data collection was to acquire a complete picture of the reference behavior and timing of user accesses to the WWW. To do this, we modified a WWW browser so as to log all user accesses. The browser we used was Mosaic, since its source was publicly available and permission has been granted for using and modifying the code for research purposes. A complete description of our data collection methods and the format of the logfiles is given in [6]; here we only give a high-level summary.
We modified Mosaic to record the Uniform Resource Locator
(URL) [1] of each
file accessed by the Mosaic user, as well as the time the file was
accessed and the time required to transfer the file from its server (if
necessary).![]() For completeness, we record all URLs accessed whether they were served
from Mosaic's cache or via a file transfer; however the distinction is
preserved in the collected data.
For completeness, we record all URLs accessed whether they were served
from Mosaic's cache or via a file transfer; however the distinction is
preserved in the collected data.
At the time of our study (November 1994 through February 1995) Mosaic was the WWW browser preferred by nearly all users at our site. Hence our results reflect the behavior of nearly all the WWW users at our site. Since the time of our study, the preferred browser has become Netscape [5], which is not available in source form. As a result, capturing an equivalent set of WWW user traces at the current time would be significantly more difficult.
In this paper we will refer to a single execution of Mosaic as a session. We will refer to the record of all URLs accessed in a session as a trace. Each trace is stored in a separate file called a log. Any file pointed to by a URL we call an object; we refer to a collection of objects that are displayed together in a page of the browser as a document.
To avoid extensive internal modifications to Mosaic, we kept no extra information in Mosaic internal data structures. As trace information was produced, it was written to log files on a local disk. At the end of a session the log was transferred to a central machine where it was stored and later processed to generate the statistics.
To instrument Mosaic we identified the routines that are invoked during requests for an object. This required source changes to the files main.c, img.c, mo-www.c, history.c, gui-documents.c, HTAccess.c, HTFTP.c, HTFormat.c, HTGopher.c, HTNews.c, HTTP.c, and HTML.c. A large number of files was modified because each module responsible for one of the possible transfer protocols (FTP, HTTP, etc.) had to be modified to write to disk the URL, the size in bytes of the object, the time the request was issued, and how long it took to retrieve the object. In addition we had to include 2 extra routines: one to verify if logs were requested; and a second to transmit the logs to the central machine.
We now realize that the decision not to maintain information inside Mosaic was not the best one, since the version of Mosaic we used has the following behavior when loading a document: after loading a document, Mosaic recalculates the display space required. If the whole document fits in the display area, Mosaic reloads the document again after modifying the display not to show the sliding rule. This reload causes an extra call to the routines that display texts and in-line images. As a result we need to carefully distinguish between the original display of an object and its redisplay if the sliding rule is eliminated. To address this, an additional tool was developed for log post processing. All of the published logs have been processed in this manner to remove artifacts of Mosaic's document re-display.
We generated logfiles in three formats, which we called: condensed, window and structure. We designed the log files for ease of post-processing, so some information is contained in more than one log format. The condensed logs contain the sequence of object requests (again, whether the object was served from the local cache or from the network). The window logs summarize the sequence of documents viewed in each window of the browser (since the browser can present multiple windows). Finally, the structure logs contain the internal structure of each document requested (consisting of the URLs for the textual part, any inlined images, and the embedded links).
The log files are named according to their contents. Each name consists of 3 segments separated by dots. The first segment describes the type of trace it contains: con, win and mos, for condensed, window and Mosaic document structure, respectively; this concatenated with a user id number. User ID numbers are converted from Unix UIDs via a one-way function that allows user IDs to be compared for equality but not to be easily traced back to particular users. The next segment consists of the the machine on which the session took place. The last segment consists of the time (in seconds since 1/1/70) when the session started.
For example, a file named con1.cs20.785526125 is a condensed log, and is a log of a session from user 1, on machine cs20, starting at time 785526125. Corresponding to this file there would also exist a window and a structure log; their names would differ only their first thee characters.
Each line of a condensed log corresponds to a single URL requested by the user; it contains the machine name, the time stamp when the request was made (seconds and microseconds since January 1, 1970), the URL, the size of the document (including the overhead of the protocol) and the object retrieval time in seconds (reflecting only actual communication time, and not including the intermediate processing performed by Mosaic in a multi-connection transfer). An example of a line from a condensed log is:
cs20 785526142 920156 "http://www.cs.bu.edu/lib/pics/bu-logo.gif" 1804 0.484092
In the condensed logs, lines with the number of bytes equal to 0 and retrieval delay equal to 0.0 mean that the request was satisfied by Mosaic's internal cache. By logging internal cache accesses, one can understand the behavior of Mosaic, in order to mimic its actions or to compare them to those of a different caching strategy. Such an approach was taken in [2].
The second log file reports the window context of the user when using the browser, i.e., the sequence of documents visited and the windows in which those documents are visited. This tracks behavior such as going ``forward'' or ``backwards'' within a window, or ``jumps'' between windows. This data is useful for behavioral studies, and could be useful in determining an empirical model of user behavior for generating synthetic loads in simulators.
Each line in this file contains: a two digit number separated by a dot, reflecting the window and the document number inside that window; the URL; and the date/time when it was accessed. Here is an example of four lines from a window history log:
1.1 "http://www.cs.bu.edu:80/" "Tue Nov 22 12:42:24 1994" 1.2 "http://www.zyxel.com/" "Tue Nov 22 12:46:42 1994" 1.3 "http://www.zyxel.com/2864.html" "Tue Nov 22 12:48:21 1994" 1.2 "http://www.zyxel.com/" "Tue Nov 22 12:53:33 1994"
The third log file contains a structural summary
of each of the documents viewed by the user.
For each document visited, the log contains a summary of the embedded
images (<IMG SRC=...>) and the embedded references (<A
HREF=...></A>).
The type of a line in the document structure log is identified by a number in the first position on the line. The number 1 signifies that the line is a URL directly requested by the user. Subsequent lines specify items contained in that URL, continuing until another line type 1 is encountered. The number 2 signifies that the line represents a contained URL, normally an in-line image. The number 3 means that the line represents a reference (anchor). The number 4 is used to indicate that the line represents a redirection; what follows is the redirected URL.
Lines in the document structure log consist of two formats. For type 1 and 2 lines, the format is: the line type; the machine name; the URL; seconds and microseconds since 1/1/70 when the request was made; the round trip retrieval time; and the item's size (including the protocol overhead). If the object's size and time are zeroes, no transfer took place, possibly because the objest was shared by other documents. For type 3 lines, the format is: the line type; the sequence number of the reference within the document (numbered sequentially starting from 0 for each document); and the reference itself. A typical segment of a document structure log is shown in Figure 1.
Sometimes Mosaic is not able to fetch parts of the whole document; for example, some in-line images. This is indicated in the document structure log by the absence of the time and size information (not shown in Figure 1). This was not considered to be a serious problem, since the main objective of this log is to discover document structure.
A possible use of the document structure log is to partially reconstruct the Web graph. With such a graph it could be possible to model access patterns for individual users with the goal of developing an intelligent agent that could help in document prefetching.
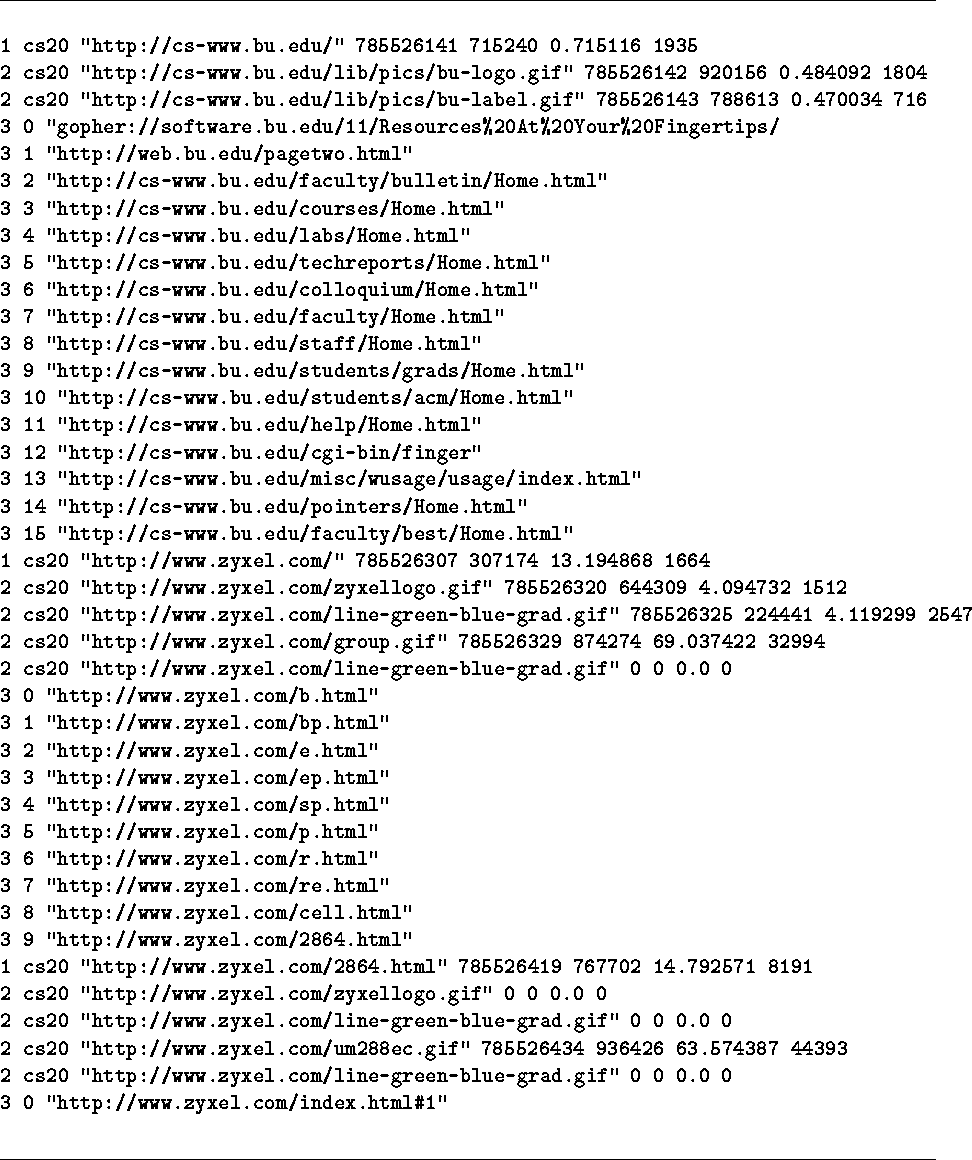
Figure 1: Typical entries in a document structure log file.
To collect our data we installed our instrumented version of Mosaic in the general computing environment at Boston University's Computer Science Department. This environment consists principally of 37 SparcStation 2 workstations connected in a local network, which is divided in 2 subnets. Each workstation has its own local disk; logs were written to the local disk and subsequently transferred to a central repository.
32 workstations were primarily used by undergraduates in the Computer Science program. We refer to these as the Room B19 workstations (and traces and users) from the name of the room they are in. 5 workstations were primarily used by graduate students. These are the Room 272 workstations (and users and traces).
We began by collecting data on the Room 272 workstations only, while testing our data collection process. This period lasted from 21 November 1994 until 17 January 1995. When we were statisfied that data collection was occurring correctly, we extended the data collection process to include the 32 undergraduate workstations; data collection then took place until 8 May 1995. Since Mosaic ceased to be the dominant browser in use by early March 1995, all of the statistics presented in subsequent sections of this report are based only on data from the period 21 November 1995 through 28 February 1995. When our statistics could be affected by the difference in collection strategies during this timeframe, we consider the 272 and B19 data separately.
During the data collection period a total of 4,700 sessions were traced, representing a population of 591 different users. A histogram of the number of sessions per day is shown in Figure 2. The Figure shows considerable variation over time. The enabling of tracing in B19 is clearly visible in the middle of the plot. However, even within each data collection regime (before or after B19 was enabled) there is considerable day-to-day variation in the WWW demand at our site as measured by user sessions.
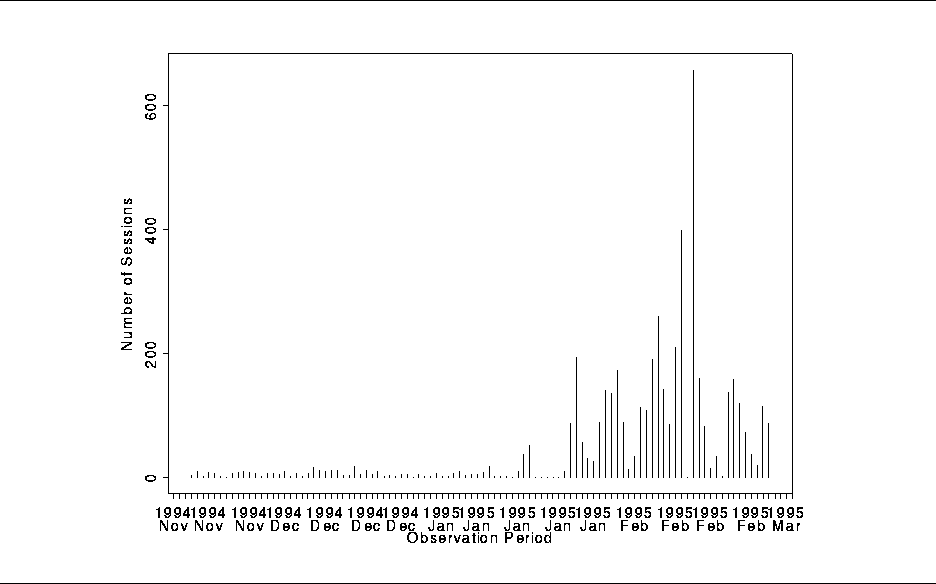
Figure 2: Histogram of the
number of sessions per day.
The users of the graduate terminal room, Room 272, consisted mainly of graduate students. There were a total of 42 users, and 527 sessions in the Room 272 data. Room 272 was open 24 hours per day.
The population using Room B19 encompasses a broader spectrum of users, including both students doing homework and less-focused users. There were 558 different Room B19 users, responsible for 4173 sessions. Room B19 was open from 9 am to 10 pm from Monday to Friday, and 12 pm to 6 pm on weekends.
Table 1 shows summary statistics on the number of sessions in each room on a daily basis. The table reflects the fact that the larger number of workstations in B19 led to a much larger number of sessions per day in that room.
Table 2 shows summary statistics on the number of sessions per user in each room. The table shows that members of the more general population in B19 used the Web fewer times overall, while the primarily graduate student population in 272 used the Web much more often.
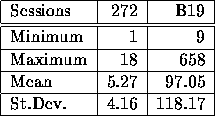
Table 1: Number of
sessions in 272 and B19 daily.
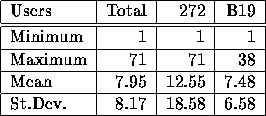
Table 2: Number of sessions
per user in 272 and B19.
Finally, Table 3 shows the distribution of requests among the different access protocols. The row Queries refers to requests containing cgi-bin in the URL. The first three columns include all the references, whether they were served by a WWW server or from Mosaic's internal cache. The second three columns consider only the requests that were statisfied by a WWW server.
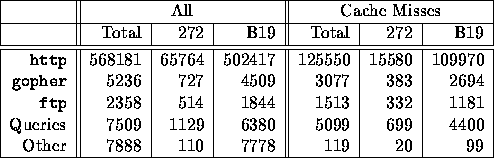
Table 3: Distribution by Protocol.
An important distinction is between those requests that went to servers outside the Boston University campus (Remote) and those requests that went to BU servers (Local). Table 4 summarizes requests based on that distinction.
The table additionally distinguishes between single references, which each occur only once in our traces, and repeated references, which occur at least twice in our traces. A reference is considered repeated if it occurs twice or more regardless of user or session boundaries. In the Table, the Unique URLs row corresponds to the number of distinct URLs while the All URLs row corresponds to all references in our dataset. Finally, the Unique Bytes row corresponds to bytes pointed to by Unique URLs while the All Bytes row corresponds to all bytes transferred in our dataset.
The distinction between Local and Remote documents can be useful, for example, in caching policies, since with the advent of fast LANs the cost associated with information retrieval inside the same institutional domain may become cheaper compared with retrievals that traverse the wide are network. An example exploration of such a distinction is discussed in [2].
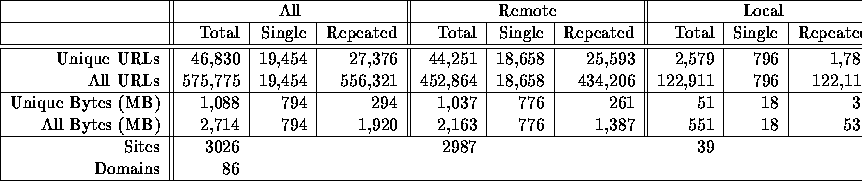
Table 4: Comparison of
Remote vs. Local Requests.
The Table shows that from a total of 575,775 requests, 452,862 were for servers outside of the BU domain. This corresponds to 78.6% of all requests. The requests include references to 3026 different sites, of which 2987 were remote and 39 were local. Table 5 summarizes the 10 top most popular sites, local and remote. In addition, Table 6 lists the most popular top-level domains.
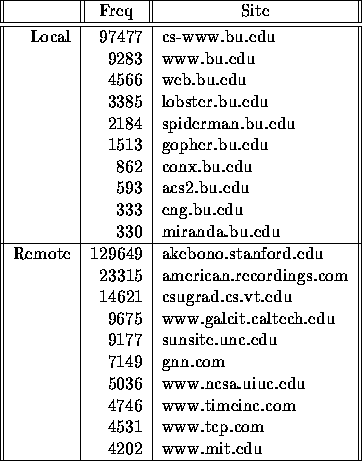
Table 5: Most Popular Sites, Local and Remote.

Table 6: Most Popular Top-Level Domains.
Since we are interested in using user profiles and user past history in directing prefetching schemes, we studied the rate of user access to new objects in the Web. To do so, we plotted diagrams showing the patterns of individual users access to new and previously seen URLs. Two such diagrams are shown in Figure 3. In these figures, the horizontal (x) axis represents successive WWW requests by a single users. Each time the user requests a previously unseen URL, that URL is assigned a new ID, which is shown on the vertical (y) axis. If the user were continually accessing new URLs (pure ``surfing'') the diagram would have a slope of 1. If the user were continually accessing the same URL, the diagram's slope would be 0. These figures show that different users exhibit different degrees of temporal locality and make different demands for new URLs, which affects the performance of document caching.
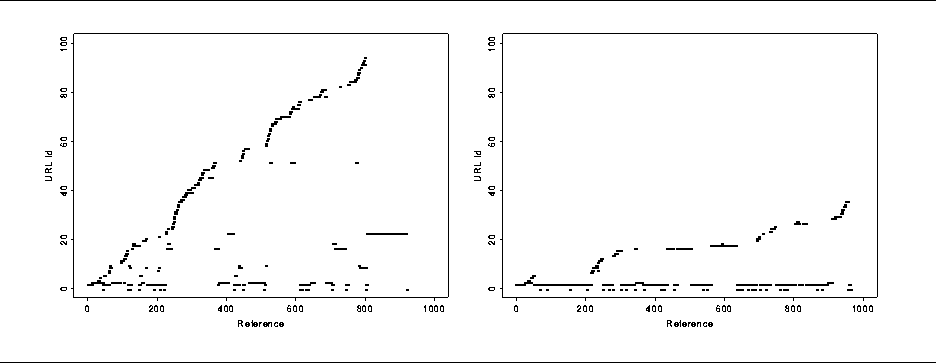
Figure 3: User Profiles. The user on the
left navigates through the Web much faster than the user on the right.
The differences between these diagrams suggest that the slope of each user's URL discovery curve could be used to parameterize a document prefetching scheme.
A primary goal of our study was to obtain a clear picture of the size distribution of the documents available on the web, of the requests made by users, and of the relationship between document size and popularity.
Previous studies of file sizes in general purpose Unix systems has shown that small sizes are much more common than large sizes [7,12]. However, in view of the potential use of the Web to publish multimedia objects, documents on the Web could have a significantly different distribution from those in general purpose file systems.
Overall, the most striking aspect of our studies of the WWW is the
dominance of the power law (or Pareto) distribution.
The shape of the power-law distribution is a hyperbola; with parameter
 its probability mass function is
its probability mass function is

and its cumulative distribution function is given by
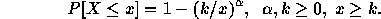
Power-law distributions have a number of properties that are qualitatively
different from distributions more commonly encountered such as the
exponential, normal, or Poisson distributions. If 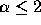 , then
the distribution has infinite variance; if
, then
the distribution has infinite variance; if 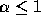 then the
distribution has infinite mean. So depending on
then the
distribution has infinite mean. So depending on  , an
arbitrarily large portion of the probability mass may be present in the
tail of the distribution --- hence the name heavy-tailed.
In practical terms a random variable that follows a heavy-tailed
distribution can give rise to extremely large values with non-negligible
probability.
, an
arbitrarily large portion of the probability mass may be present in the
tail of the distribution --- hence the name heavy-tailed.
In practical terms a random variable that follows a heavy-tailed
distribution can give rise to extremely large values with non-negligible
probability.
Figure 4 shows the size distribution of objects referred to at least once in our logfiles. Although this is not a random sample of documents available on the Web, it provides a reasonable estimate of the actual size distribution of Web documents. On the left of the Figure is a histogram of file sizes up to 6400 bytes; on the right is a histogram on a log-log scale of file sizes of 1280 bytes or more.
Figure 4 shows the pronounced
hyperbolic distribution of file sizes. The linear fit to the
log-transformed data (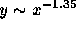 ) is very strong, with an
) is very strong, with an 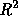 value of 0.96.
value of 0.96.
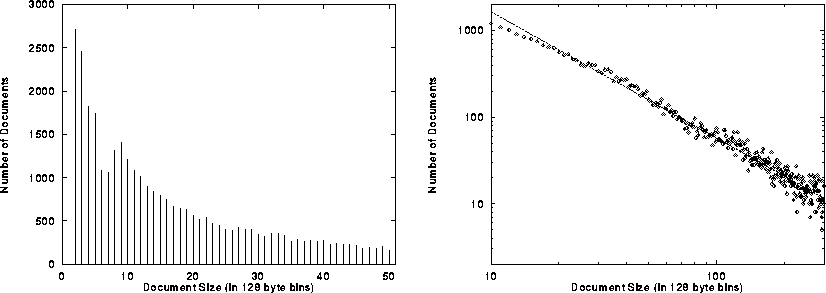
Figure 4: Document size distribution; Left: Linear scale of sizes up to 6400
Bytes; Right: Log-Log scale of sizes 1280 bytes or more.
A comparison of WWW document sizes with the file size distribution that might be found in a typical Unix file system is instructive. While there is no truly ``typical'' Unix file system, an aggregate picture of file sizes on over 1000 different Unix file systems is reported in [10]. In Figure 5 we compare the distribution of document sizes we found in the Web with that data. The Figure plots the percentage of all files in exponentially increasing bins, on a log-log scale.
Surprisingly, Figure 5 shows that in the Web, there
is a stronger preference for small files than in Unix file systems.
![]() The Web strongly favors documents in the 256 to 512 byte range, while
Unix files are more commonly in the 1KB to 4KB range. More
importantly, the tail of the distribution of WWW files is not nearly as
heavy as the tail of the distribution of Unix files. Thus, despite the
inclusion of multimedia in the Web, we conclude
that Web documents are currently more biased toward
small files than are typical Unix file systems.
The Web strongly favors documents in the 256 to 512 byte range, while
Unix files are more commonly in the 1KB to 4KB range. More
importantly, the tail of the distribution of WWW files is not nearly as
heavy as the tail of the distribution of Unix files. Thus, despite the
inclusion of multimedia in the Web, we conclude
that Web documents are currently more biased toward
small files than are typical Unix file systems.
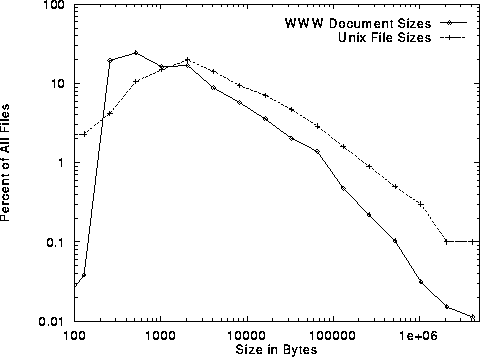
Figure 5: Comparison of Unix File Sizes with WWW File Sizes
Related to the question of document size distribution are questions involving user preferences: the relationship between size and popularity, and the popularity of individual documents.
To explore the influence of user choice on the distribution of documents
actually transferred through the Internet, we measured the relationship
between the
number of times a document is accessed and the size of the document.
Figure 6 shows a plot of the average number of
times documents of a given size (in 1K bins) were referenced. The data
shows that there is an inverse correlation between file size and file
popularity. The line shown is a least squares fit to a log-log
transform of the data (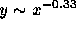 ). This fit is statistically
significant at a 99.9% level, but only explains a small part
of the total variation (
). This fit is statistically
significant at a 99.9% level, but only explains a small part
of the total variation (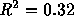 ).
).
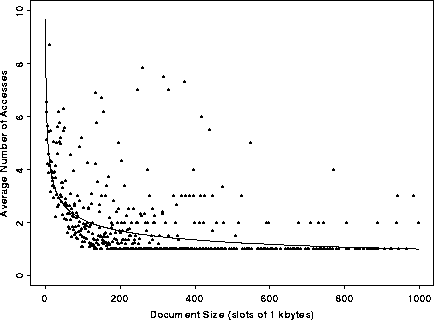
Figure 6: Distribution of Average Number of Requests by File Size.
Thus, in addition to the tendency for WWW documents as created to be small,
users additionally prefer small documents. The combined effect of
these two trends is shown in Figure 7. This figure shows
the distribution of document requests made by users, by request size. This
figure shows that actual document traffic generated by user requests also
follows a hyperbolic distribution. The least squares fit line (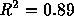 ) is
) is 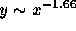 . Note that the exponent in the distribution
of request sizes, -1.66 (indicating a strong preference for transferring
small files) is very nearly the sum of the exponent describing user
preference, -0.33 (a mild user preference for small files) and the exponent
in the document size distribution, -1.35 (a moderate producer preference
for small files). Thus at the present time, the distribution of transfer
sizes is more strongly determined by document sizes than by user
preferences, although both contribute.
. Note that the exponent in the distribution
of request sizes, -1.66 (indicating a strong preference for transferring
small files) is very nearly the sum of the exponent describing user
preference, -0.33 (a mild user preference for small files) and the exponent
in the document size distribution, -1.35 (a moderate producer preference
for small files). Thus at the present time, the distribution of transfer
sizes is more strongly determined by document sizes than by user
preferences, although both contribute.
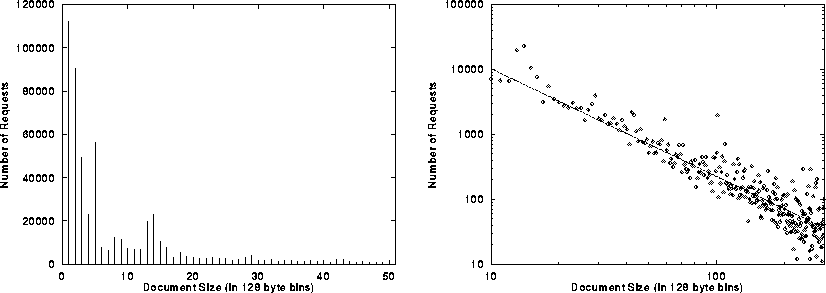
Figure 7: Distribution of Requests for Documents by
Size; Left: Linear scale of sizes up to 6400
Bytes; Right: Log-Log scale of sizes 1280 bytes or more.
The final instance of hyperbolic distributions in our data occurs as an
instance of Zipf's law [15, discussed in [11],]. Zipf's
law was originally applied to the relationship between a word's popularity
in terms of rank and its frequency of use. It states that if one ranks
the popularity of words used in a given text (denoted by 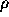 ) by their
frequency of use (denoted by P) then
) by their
frequency of use (denoted by P) then

Note that this distribution is parameterless, i.e., 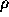 is
raised to exactly -1, so that the nth most popular document
is exactly twice as popular as the 2nth most popular document.
Zipf's law has subsequently been applied to other examples of popularity in
the social sciences.
is
raised to exactly -1, so that the nth most popular document
is exactly twice as popular as the 2nth most popular document.
Zipf's law has subsequently been applied to other examples of popularity in
the social sciences.
Our data shows that Zipf's law applies quite strongly to documents on the
WWW. This is demonstrated in Figure 8 for all 46,830
documents referenced in our logs. The figure shows a log-log plot of
references to each document as a function of the document's rank in overall
popularity. The tightness of the fit to a straight line is remarkable
(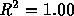 ), as is the slope of the line: -0.986. Thus the exponent
relating popularity to rank for WWW documents is very nearly -1, as
predicted by Zipf's law.
), as is the slope of the line: -0.986. Thus the exponent
relating popularity to rank for WWW documents is very nearly -1, as
predicted by Zipf's law.
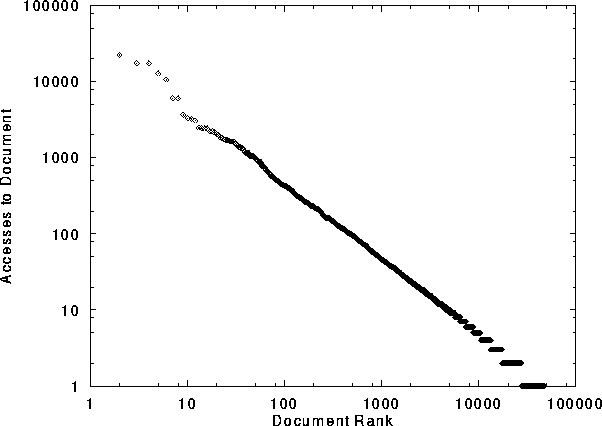
Figure 8: Zipf's Law Applied To WWW Documents
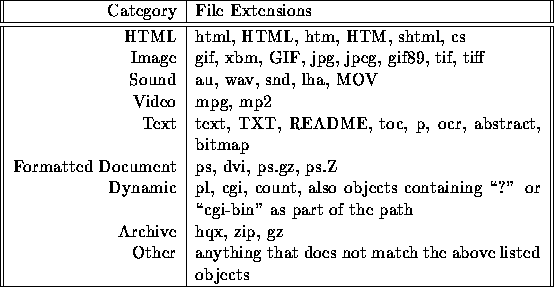
One interpretation for our file size distribution data is based on file type. It may be that (smaller) HTML files are preferred by users over (larger) images, leading to user preference for small files. To investigate this, we classified WWW objects into 9 categories, based mainly on file extension, as described in Table 7. The distribution of document requests by type is shown in Table 8. This table shows that user preference for small documents is not due to a preference for HTML files over images; in fact, the reverse is true --- image files are by far the most commonly requested object, and they tend to be significantly larger than HTML files.
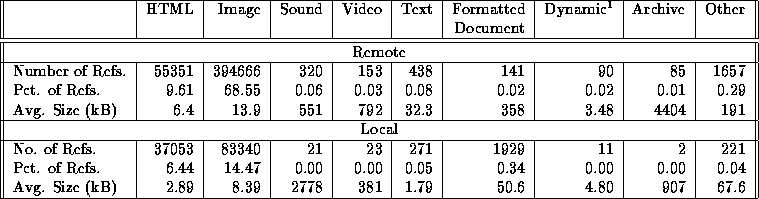
Table 8: Document Type Distribution.
This section shows how our data can be used in WWW caching strategies. In previous work, we used the raw data from our traces to drive extensive event-driven simulations of client-based caching protocols [2]. However, it is also possible to use the distributional results discussed in the last section to gain considerable insight in designing caching strategies. In this section we show a case study of how our high-level distributions can be used to guide caching policies for WWW documents.
Traditional studies of caching policies such as page replacement policies or cache-line replacement policies have been concerned with fixed-size transfer units. In contrast, caching WWW documents involves variable-sized units; as a result it is interesting to investigate what leverage can be gained through the use of document size information in caching policies. The distributional data presented in the previous section is well suited to helping answer this question.
Our goal in developing new caching strategies is to reduce the latency of WWW document accesses; thus we need an understanding of the relationship between document size and transfer cost. A complete study of the transfer time as a function of document size is beyond our scope, but we can develop a rough model for the relationship using our trace data. We will assume that document transfer time is the sum of a fixed overhead plus a per-byte cost:

where s is the size of a document in bytes. For both O and B we
will assume the average value that these terms take in our
data.![]() These parameters can be
inferred from Figure 9, which shows the average transfer
time of documents in our traces as a function of their size. Note that
as s grows the influence of O is reduced and
These parameters can be
inferred from Figure 9, which shows the average transfer
time of documents in our traces as a function of their size. Note that
as s grows the influence of O is reduced and 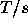 approaches the
constant B.
approaches the
constant B.
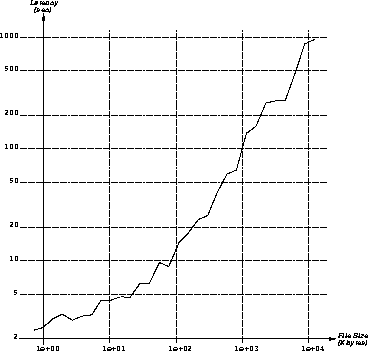
Figure 9: Transfer Time of Documents as a Function of Size
To include size information in a caching strategy, we would like to know the expected total improvement in latency for each byte that is cached, as a function of file size. Using that information we can decide whether to cache a file based on its size, and we can determine how much improvement in total latency can be gained from a size-based caching policy.
The data presented in the previous section provides the tools to answer this question. We consider a proxy-type cache, in which all requests in our traces are forwarded through a local server. Thus we treat all our traces in the aggregate as a single reference stream. Then we can calculate the total improvement in latency for each byte that is cached, L, as:
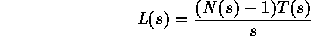
where N(s) is the expected number of references to a document of size s, as shown in Figure 6. This equation yields the total document transfer latency that will be avoided by caching a document of size s, per byte of cache space used.
Note that we have assumed that a document, once cached, has zero retrieval cost in the future. Since we can also derive O and B estimates for local documents, we could include the cost of local transfers for future accesses to the cached documents. However, doing so does not significantly change the results that we present.
A plot of L as a function of s is shown in Figure 10.
The figure is plotted on log-log axes, and for file sizes greater than
1K bytes, is roughly linear. Thus we see that latency savings per byte
is asymptotically hyperbolic, as we would expect from the equation for
L, since  is asymptotically linear, and N is hyperbolic (as
discussed in the previous section).
is asymptotically linear, and N is hyperbolic (as
discussed in the previous section).
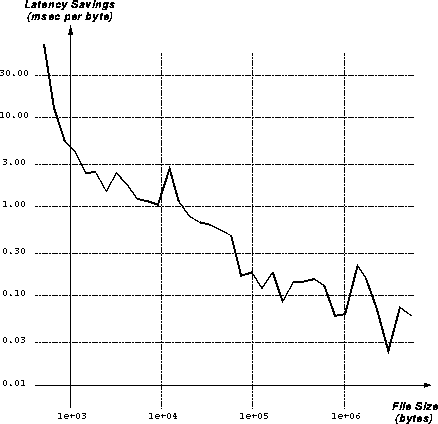
Figure 10: Latency Savings per Byte as a Function of Document Size
The most important aspect of Figure 10 is that it is monotonically decreasing, which means that WWW cache space should be preferentially allocated to smaller files over larger files. The reasons why cache space should be allocated to small files preferentially derive directly from the user preferences shown in Figure 6 and from the relatively large latency savings gained by avoiding the fixed cost overhead O in transferring small files.
However, these curves do not reflect the cost of allocating resources for file caching. In particular, we would like to know how much space will be required, and what the expected benefit will be, if we adopt a policy of caching all files less than a certain size.
To answer this question, we must first find the amount of cache space
required to cache all files less than a certain size. This
can be done by simply performing a running sum over the distribution
shown in Figure 4, times its x axis. The result
is shown in Figure 11; in the figure, the x
axis is logarithmic while the y axis is linear. The figure shows that
(for file sizes greater than 10K) the amount of cache space required
increases logarithmically as a function of the largest file size cached.
This is reasonable, since if the distribution of remote files is
hyperbolic with exponent close to -2, then
multiplying by x adds 1 to the exponent and integrating
yields the 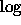 function. Although we found the distribution of all
files to be approximately
function. Although we found the distribution of all
files to be approximately 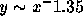 , the effect of selecting only
remote files is to decrease the likelihood of large files, thus moving
the exponent in the underlying distribution closer to -2.
, the effect of selecting only
remote files is to decrease the likelihood of large files, thus moving
the exponent in the underlying distribution closer to -2.
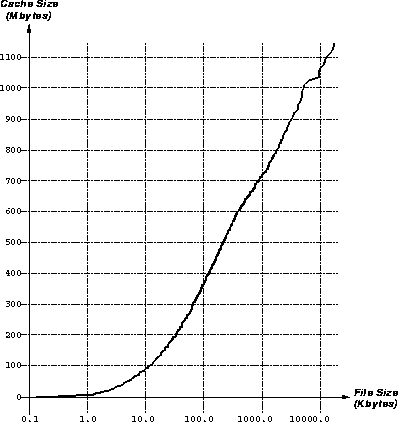
Figure 11: Cache Space Required as a Function of File Sizes Cached
Using the resulting distribution of cache sizes as a function of file sizes cached, we can predict the effect of caching using various cache sizes. We replot the data in Figure 10 as follows. Instead of plotting the latency savings per file size, we plot the latency savings against the cache size corresponding to the proper file size. The result is shown in Figure 12. On the left is the function on linear axes; on the right it is plotted on log-log axes.
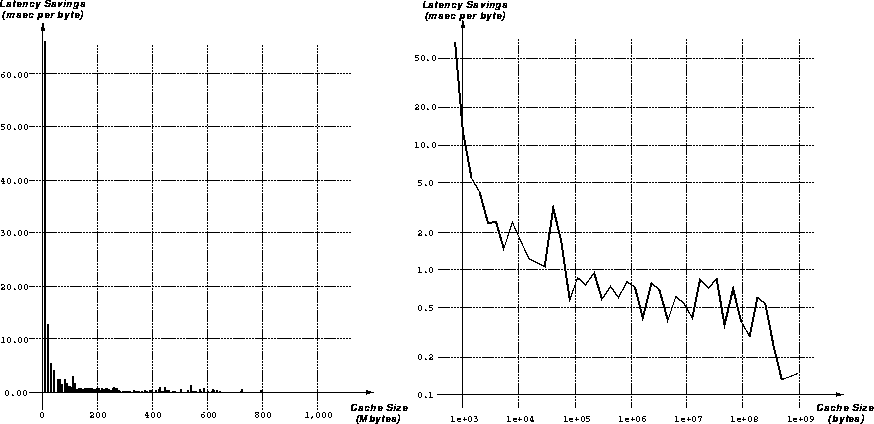
Figure 12: Latency Savings as a Function of Cache Size
Finally, we can determine the percent of total possible savings that are gained by caching as a function of cache size allocated. This is simply the running summation of the distribution shown in Figure 12. The resulting summation is shown in Figure 13.
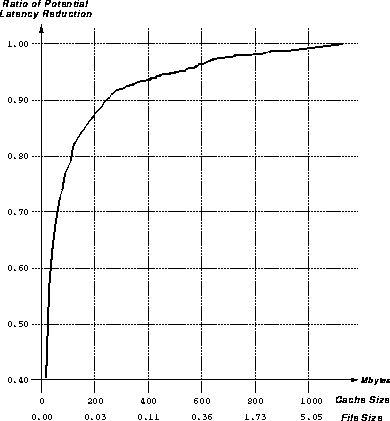
Figure 13: Fraction of Total Latency Savings as a Function of Cache Size
This figure shows the fraction of total latency in our traces that can be saved using a caching policy that caches all documents less than a certain size. The amount of cache space needed is shown on the x axis, and below that, the cutoff size of the documents to be cached for that size cache. The figure shows that with only 400MB of cache space, approximately 95% of maximum possible performance gains can be achieved. At this level, the cutoff size for documents would be approximately 110KB.
More importantly, the figure shows how sharp the improvement is in performance as cache size is increased from 0 to 100MB. In this region the improvement is approximately linear, which means that cache space can be distributed among the various file sizes without great changes in performance. This flexibility means that strategies that choose to cache a few large files (to improve worst-case latency) or many small files (to improve the most common case) are equally attractive.
It is clear that the World Wide Web is presenting a challenge to network managers and, moreover, to computer scientists. The growth pattern of the WWW suggests that careful use of the network, CPU, and disk resources that support the Web will become increasingly important over time.
To support our future research on WWW resource management, we have collected and described a large amount of data reflecting actual user accesses to the Web. Our data is unique as it has been collected by instrumenting clients rather than servers, and because it provides insight into demands that Web users make on disk and CPU as well as network resources.
In summarizing our data, we have identified a number of trends and reference patterns in WWW use. In particular, we have shown that many characteristics of WWW use can be modeling using power-law distributions, including the distribution of document sizes, the popularity of documents as a function of size, the distribution of user requests for documents, and the number of references to documents as a function of their overall rank in popularity. In addition, we have shown that even high-level, distributional information about WWW use can be helpful in designing caching strategies for WWW documents.