A Bayesian Approach for Online Classifier Ensemble
We propose a Bayesian approach for recursively estimating the classifier weights in online learning of a classifier ensemble. In contrast with past methods, such as stochastic gradient descent or online boosting, our approach estimates the weights by recursively updating its posterior distribution. For a specified class of loss functions, we show that it is possible to formulate a suitably defined likelihood function and hence use the posterior distribution as an approximation to the global empirical loss minimizer. If the stream of training data is sampled from a stationary process, we can also show that our approach admits a superior rate of convergence to the expected loss minimizer than is possible with standard stochastic gradient descent.
For more details ICML'14 paper, full version, Slides.
Downloads
[Code*] [Dataset* + Result*]
* Coming soon!
[BibTex]
@inproceedings{bai2014bayesian,
title={A Bayesian framework for online classifier ensemble},
author={Bai, Qinxun and Lam, Henry and Sclaroff, Stan},
booktitle={Proceedings of the 31st International Conference on Machine Learning (ICML)},
year={2014}
}
Online Ensemble Learning
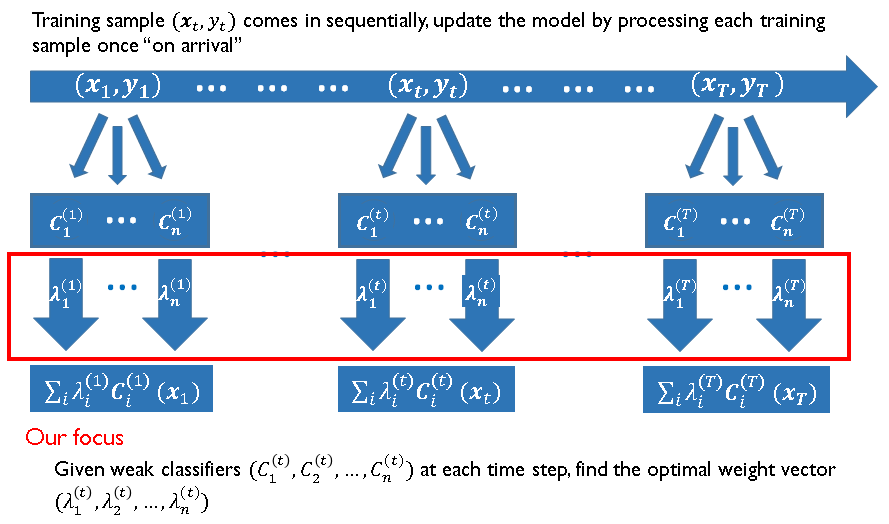 |
A Stochastic Optimization Problem
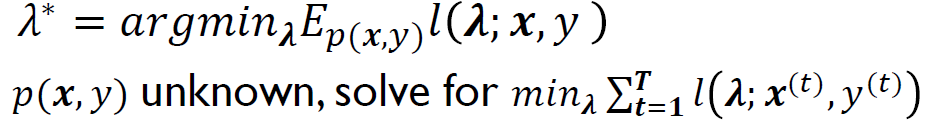 |
Motivation
Two classical results in Bayesian statistics- The Bayesian posterior distribution tends to peak at the MLE of the same likelihood function.
- MLE minimizes the expected negative log-likelihood.
- Above results hold regardless of whether the likelihood actually describes the data generating proces or not.
- Derive an artifitial likelihood from a predefined loss function and run the recursive Bayesian procedure.
Main results
A Bayesian scheme for online classsifier ensemble- Formulate as a stochastic optimization problem and estimate the ensemble weights through a recursive Bayesian procedure.
- Under some regularity conditions, converges to global optimum, in contrast with many local methods.
- Convergence rate superior to standard stochastic gradient descent, in terms of asymptotic variance. Empirically outperforms state-of-the-art SGD methods.
- Promising performance in experiments compared with online boosting methods.