- Review the basics of graph random walks
- Work through an example showing how it can be solved via simulation
- Show the link between random walks and the PageRank algorithm
- Work through a series of examples using the PageRank simulator
- Consider the pitfalls of PageRank
Plan:
- Recall that in a random walk, an individual walker follows the
process below:
- Start in some random node
- At random select one of the outgoing edges of the current node
- Walk over that edge to a new node
- Go to 2
Note that in general the edges out of a node may be labeled with the probability that they would be selected by the walker (i.e., the edges do not have to be equally likely selected).
- In general, we are interested in how a very large number of
walkers (a population of walkers) would end up covering the various
nodes in the graph.
The particular question we want to answer is to figure out the proportion (percentage) of the population at each node after having the walkers roam the graph for a very long time. Thus, for a node X, we want to find Pr(X).
- Recall that one way to do this (as we have done in class) is to
establish relationships between the proportion of the population at
each node, noting that they must all add up to 100%.
Use the example below (which I showed in lecture but did not solve) to derive these relationships.
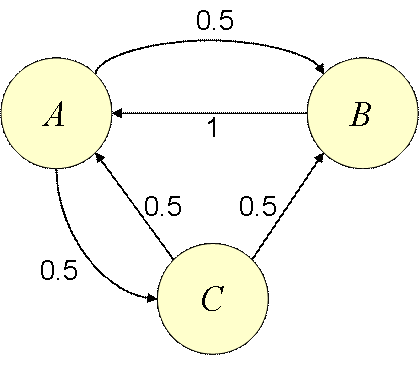
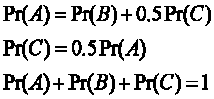
- Show that simple substitutions would lead to the following
solution
- Pr(A)=0.44
- Pr(B)=0.33
- Pr(C)=0.22
- This analytical approach is good for small graphs, but cannot be
used for very large graphs.
For large graphs, we can do a simulation that follows the process below:
- Start with a population of 100 that we divide equally across the nodes.
- Take one simulation step, moving a proportion of the population from each node to every one of its neighboring nodes in accordance with the weight on the edges
- Go to 2 until the number of steps exceeds some threshold (say 15).
At the end of the above process, the population at each node is an estimate of the solution we would get analytically.
- Show how this would work on the above graph.
The following are the first few iterations of the above "simulation":
Iteration Pr(A) Pr(B) Pr(C) 0 33.33 33.33 33.33 1 50.00 33.33 16.67 2 41.66 33.33 25.00 3 45.83 33.33 20.83 4 43.75 33.33 22.91 5 44.79 33.33 21.87 6 44.27 33.33 22.39 7 44.53 33.33 22.13 8 44.40 33.33 22.26 9 44.46 33.33 22.20 10 44.43 33.33 22.23 11 44.45 33.33 22.21 12 44.44 33.33 22.22 13 44.44 33.33 22.22 14 44.44 33.33 22.22 15 44.44 33.33 22.22 Here is a link to the above Excel spreadsheet. Download it and play with it, noting that it really does not matter what initial conditions we have for the population at time zero, since at the end the proportions of the populations in A, B, and C will be the same (and the same as analysis).
- A random walks on a graph is not a great way to
model the surfing behavior on the web (or facebook or Twitter)
because it assumes that all visits to a page are through links from
another page, which is not the case on the web since a number of the
visits will be due to users just going directly to the page (e.g.,
typing a URL). That said, the model can be modified to allow for
a fixed percentage of the visits to the page to be through random
walking (e.g., 85%), while the rest (e.g., 15%) would be from direct
visits to the page.
This yields the PageRank algorithm (at the heart of the technology that started Google).
- Download and run the
PageRank
Simulator. A zipped directory containing the program, tutorials,
and examples used in this module is available
here.
This simulator requires that you have Java installed on your PC.
- One can create a graph of pages pointing to each other.
This is done by
- Clicking on "New Page" and then clicking in the work area. Each time one does that a new page is added.
- Clicking on "New Link" and then clicking on one of the pages already created and dragging the mouse to another page. This add a directed link from the first page to the second.
- On the left panel of the simulator, you will see the pages
you added grouped under a heading (by default it will be
"Untitled1". You can highlight that group name by clicking on
it. Now, you can change the property of that group by clicking
on "Edit Properties" which is under the "Edit" menu.
The most important "property" for our purposes is the damping factor (misspelled as "dump" factor in the simulator), which is set to 0.85 (the Google PageRank default). If you change the damping factor to 0.99, you will get the simulation of a random walk as opposed to PageRank.
- By clicking on the "Page Rank" button, the tool runs a
simulation and displays the scores (rank) of the various pages.
Notice that if you set the damping ratio to 0.99 you would be
getting the proportions of the population visiting the various
pages (as we did before).
- Experiment with both PageRank and Random Walk on a number of
graphs of progressive complexity. Here are a number of
"projects" you can try. You can download these and save them to
your computer and then open them up from the PageRank simulator
(by clicking on "Open Project" from the file menu).
- Example 1: 2 nodes (P0 <--> P1 )
- Example 2: 3 nodes (P0 <--> P1 + P0 <--> P2)
- Example 3: 3 nodes (same as Example 2 + P2 <--> P1)
- Example 4: 9 nodes
- Example 5: 9 nodes (same as Example 4, with damping =0.85)
- Example 6: Google Bomb example (before bomb)
- Example 7: Google Bomb example (after bomb)
Except for Examples 5, 6, and 7, the damping factor is 0.99 (i.e., PageRank = Random Walk).
- One can create a graph of pages pointing to each other.
- Think about and discuss the pitfalls from using a single
algorithm to rank the popularity of web pages
- Knowledge of the algorithm could result in attempts to alter
the structure of the web to "boost" the rank of specific pages,
with the extreme cases of using "Google Bombs" as exemplified in
this
Wikipedia article on the infamous 2004 Elections "Miserable
Failure" Google Bomb.
- Given Google's success, people are increasingly using it to surf the web. This in turn is making the structure of the web less prominent (or secondary) to Google's ranking. But, Google's ranking depends on the structure of the web! Thus an interesting question is whether Google's success is undermining the main reason for its success?!
- Knowledge of the algorithm could result in attempts to alter
the structure of the web to "boost" the rank of specific pages,
with the extreme cases of using "Google Bombs" as exemplified in
this
Wikipedia article on the infamous 2004 Elections "Miserable
Failure" Google Bomb.